5X File Loads from Object Storage with DBMS_CLOUD.COPY_DATA

Introduction
When dealing with loading large volumes of data into my APEX Apps, I typically follow this pattern:
Have third-party systems post data files to OCI Object Storage.
Use OCI Events to have OCI call an ORDS Service to inform the Database that a file is ready to load.
The ORDS Service launches an APEX Automation to fetch the file from OCI Object Storage using APEX_WEB_SERVICE, use APEX_ZIP to Unzip the file then APEX_DATA_PARSER.PARSE to parse and load the file into a DB table for further processing.
You can read more about this approach by reading this post, 'Event-Driven Integration with OCI Events, ORDS, & APEX'.
This pattern usually works well, but loading very large files from OCI Object Store to a database table using APEX_DATA_PARSER can be slow.
The Approach
When you call the dbms_cloud.copy_data PL/SQL API, the following steps are performed:
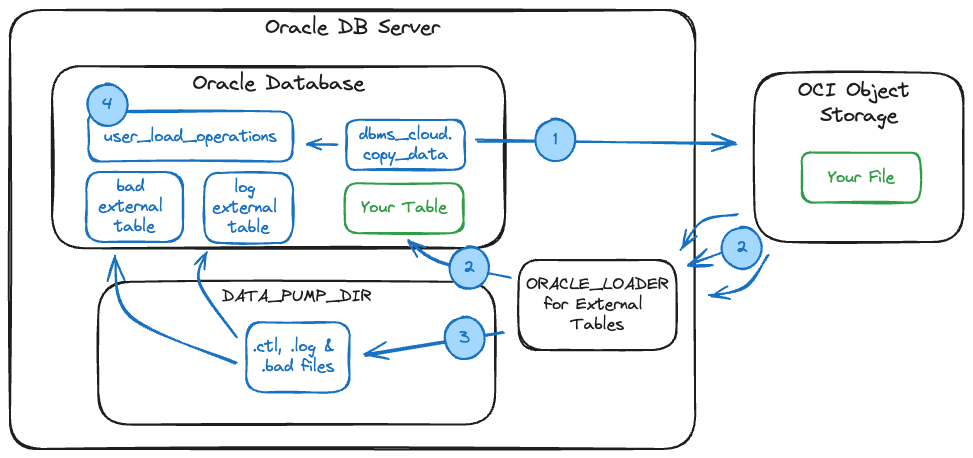
Make the call to dbms_cloud.copy_data.
dbms_cloud.copy_data uses ORACLE_LOADER for External Files (similar to SQL*Loader) to parse and stream the file's content (in parallel) to your table in the database directly from Object Storage.
Artifacts from the load (.log and .bad files) are created in the DATA_PUMP_DIR of your database, and external tables (COPY$XXX_LOG and COPY$XXX_BAD) are created pointing to these files.
Write a record to the table
user_load_operationswith status, names of log and bad files, and a record count.
dbms_cloud.copy_data streams the content of your file and parses the content in parallel.Preparing for the Performance Test
We need to put a few things in place before we can test the performance of dbms_cloud.copy_data vs using APEX_DATA_PARSER.
Test Data Preparation
I am using California EV Sales data to run the tests. You can get the Excel of the data here. I converted the data to CSV and duplicated the data set a few times to get a total of 94,025 records (about 4 MB).
The first 3 rows of the CSV file look like this:
data_year,county,fuel_type,make,model,number_of_vehicles
1998,Los Angeles,Electric,Ford,Ranger,1
1998,Orange,Electric,Ford,Ranger,1
Using the script below, I created a no-frills table to load the data into.
CREATE TABLE "EV_SALES_BY_YEAR"
("DATA_YEAR" NUMBER NOT NULL,
"COUNTY" VARCHAR2(50) NOT NULL,
"FUEL_TYPE" VARCHAR2(50) NOT NULL,
"MAKE" VARCHAR2(50) NOT NULL,
"MODEL" VARCHAR2(50) NOT NULL,
"NUMBER_OF_VEHICLES" NUMBER NOT NULL);
OCI Setups
You will need to perform the following OCI Setups:
Database Setups
Grants
You need to perform the following grants for your database user <YOUR_USER>:
GRANT EXECUTE ON dbms_cloud TO <YOUR_USER>;
GRANT READ,WRITE ON directory DATA_PUMP_DIR TO <YOUR_USER>;
Credential
Create a credential using dbms_cloud.create_credential. The values are the same as the ones used for creating the Oracle APEX Web Credential in the post I mentioned previously.
BEGIN
dbms_cloud.create_credential
(credential_name => 'obj_store_dbms_cloud_test',
user_ocid => 'ocid1.user.oc1..aaaaaaaae...',
tenancy_ocid => 'ocid1.tenancy.oc1..aaaaaaaa...',
private_key => 'MIIEvQIBADANBgkqhkiG9w0BAQEFAASCBKcwgg...',
fingerprint => 'b9:53:5a:44:t3:5a:1e:f1:27:3b:08:81:32:c6:32:46');
END;
The Performance Tests
🎬 OK, now we are ready to run the performance tests.
APEX_DATA_PARSER
Here is the code to perform the load using APEX_DATA_PARSER and APEX_ZIP. You may also notice that I used dbms_cloud.get_object to get the zip file from Object Storage. You can use this as an alternative to APEX_WEB_SERVICE if you like.
BEGIN
-- Truncate the Table before loading.
EXECUTE IMMEDIATE 'TRUNCATE TABLE EV_SALES_BY_YEAR';
-- Fetch the File from OCI, Unzip it, Parse it and Load It.
INSERT INTO EV_SALES_BY_YEAR (DATA_YEAR,COUNTY,FUEL_TYPE,MAKE,MODEL,NUMBER_OF_VEHICLES)
SELECT col001 data_year
, col002 COUNTY
, col003 FUEL_TYPE
, col004 MAKE
, col005 MODEL
, col006 NUMBER_OF_VEHICLES
FROM apex_data_parser.parse
(p_content => apex_zip.get_file_content
(p_zipped_blob => dbms_cloud.get_object
(credential_name => 'obj_store_dbms_cloud_test',
object_uri => 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/xxxxx/b/dbms_cloud_test/o/CA_EV_Sales.csv.zip'),
p_file_name => 'CA_EV_Sales.csv'),
p_skip_rows => 1,
p_detect_data_types => 'N',
p_file_name => 'CA_EV_Sales.csv');
END;
DBMS_CLOUD.COPY_DATA
The code to load the data using dbms_cloud.copy_data looks like this. I have included comments to describe each of the parameters.
DECLARE
l_operation_id user_load_operations.id%TYPE;
BEGIN
-- Truncate the table prior to load.
EXECUTE IMMEDIATE 'TRUNCATE TABLE EV_SALES_BY_YEAR';
-- Stream, Parse and Load the File.
dbms_cloud.copy_data
-- Table we want to load data into.
(table_name => 'EV_SALES_BY_YEAR',
-- Credential we created above using dbms_cloud.create_credential
credential_name => 'obj_store_dbms_cloud_test',
-- CSV List of fields from the CSV file,
-- listed in the same order as columns in the table.
-- The field names do not have to match the column names.
-- It is a good idea to specify field sizes for VARCHAR2 columns
-- as I have done here. Otherwise, dbms_cloud.copy_data
-- assumes a default of only 240 characters.
field_list => 'data_year,county CHAR(50),fuel_type CHAR(50),make CHAR(50),model CHAR(50),number_of_vehicles',
-- File name, CSV List of Files, or Wildcard Expression
-- representing the file(s) to load.
file_uri_list => 'https://objectstorage.us-ashburn-1.oraclecloud.com/n/xxxx/b/dbms_cloud_test/o/CA_EV_Sales.gzip',
-- Variable returned by dbms_cloud.copy_data with
-- the ID of the load. Track Progess of the load by
-- querying user_load_operations WHERE id = l_operation_id
operation_id => l_operation_id,
-- JSON_OBJECT containing details required to perform the load.
-- type: CSV File, coompression: File is compressed by gzip
format => json_object ('type' value 'csv',
'compression' value 'gzip',
'skipheaders' value '1',
'delimiter' value ',',
'ignoremissingcolumns' value 'true' ));
END;
More on DBMS_CLOUD.COPY_DATA
Checking the Result of a Load
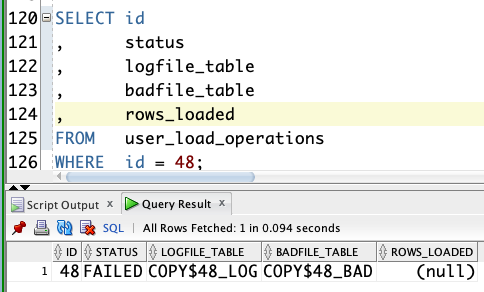
You can track the result of the load by querying the table user_load_operations. You can get the ID for the current load from the parameter operation_id.
SELECT id
, status
, logfile_table
, badfile_table
, rows_loaded
FROM user_load_operations
WHERE id = 48;
You can then query the Log and Bad File external tables (created by dbms_cloud.copy_data) to get more details of any errors that occurred. These external tables point to the log and bad files on the database file system that ORACLE_LOADER generated.
Log File External Table:
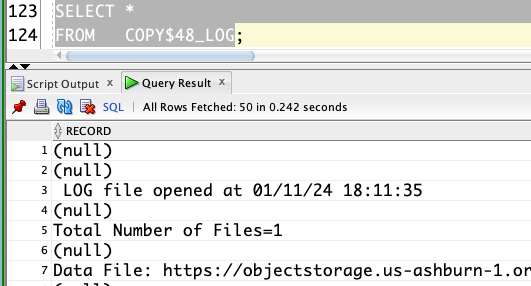
Bad File External Table:
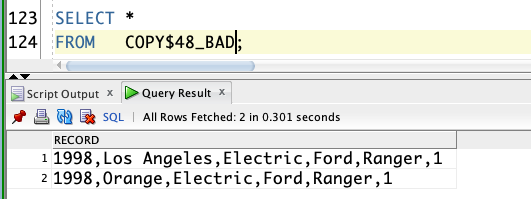
rows_loaded column of the table user_load_operations to get a count of rows loaded from the file for auditing purposes.Errors & Potential Exceptions
This section describes some scenarios where you may encounter exceptions.
Required Column in Table not Included in File
If I remove the number_of_vehicles column from the CSV file (which is required in the table) as follows:
data_year,county,fuel_type,make,model
1998,Los Angeles,Electric,Ford,Ranger
1998,Orange,Electric,Ford,Ranger
Result: ❌ Error. The following exception is raised by dbms_cloud.copy_data:
Error report -
ORA-20000: ORA-01400: cannot insert NULL into
("CNAPPS"."EV_SALES_BY_YEAR"."NUMBER_OF_VEHICLES")
Extra Column in CSV File not in Table
Having an extra column in the CSV file that is not represented in the table is fine. In this example, the extra column does not exist in the table.
data_year,county,fuel_type,make,model,number_of_vehicles,extra
1998,Los Angeles,Electric,Ford,Ranger,1,2
1998,Orange,Electric,Ford,Ranger,1,2
Result: ✅ Success
File Column Name Does not Match Table Column Name
If the column name in the CSV file does not match the column name in the DB table (the last column should be number_of_vehicles, not num_vehicles).
bannanas,county,fuel_type_apples,make,model,num_vehicles
1998,Los Angeles,Electric,Ford,Ranger,1
1998,Orange,Electric,Ford,Ranger,1
Result: ✅ Success. The columns in the CSV file must be in the same order as the DB table but do not have to have the same name.
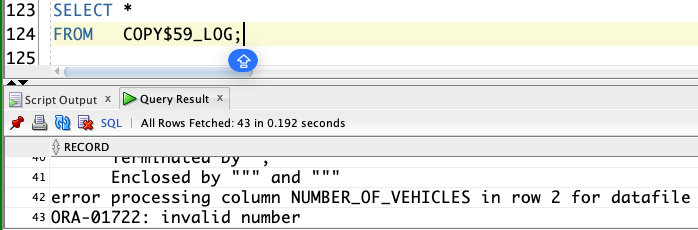
Invalid Value in File
What if you have invalid values in the file? In this example, row 2 has an invalid value (non-numeric) for number_of_vehicles.
data_year,county,fuel_type,make,model,number_of_vehicles
1998,Los Angeles,Electric,Ford,Ranger,ABC123
1998,Orange,Electric,Ford,Ranger,1
Result: ❌ Error. In this case, an exception is raised:
Error report -
ORA-20003: Reject limit reached, query table "CNAPPS"."COPY$59_LOG" for error details
ORA-06512: at "C##CLOUD$SERVICE.DBMS_CLOUD", line 1822
We can check the external LOG table for details of the error:
Handling Dates
You can specify a specific date or timestamp format in the field_list parameter like this:
'model_release_date CHAR(22) date_format DATE mask "YYYY-MM-DD"T"HH24:MI:SS"'
If all your date/timestamp fields are formatted the same, you can set the format strings by passing values for dateformat and or timestampformat in the format parameter json_object. e.g.
format => json_object ('type' value 'csv',
'skipheaders' value '1',
'timestampformat' value 'YYYY-MM-DD"T"HH24:MI:SS',
'delimiter' value ','));
Other Considerations
Here are some other things to consider when working with dbms_cloud.copy_data
While dbms_cloud.copy_data does a lot of the heavy lifting for you, you still need to put controls around it, including handling errors gracefully and verifying file record counts vs. loaded record counts, etc.
dbms_cloud.copy_data allows you to load multiple files at a time.
It is good practice to include the size of your VARCHAR fields in the
field_listparameter. dbms_cloud.copy_data assumes 240 characters for a VARCHAR filed by default.dbms_cloud.copy_data does not support ZIP compression. It does support
gzip,zlib, andbzip2. If you set thecompressionoption toauto, it will determine the compression type for you.Even though I have featured CSV in this post, you can also load Avro, Datapump, Orc, Parquet, and JSON formatted files using dbms_cloud.copy_data.
You can also use dbms_cloud.copy_data to load data from sources other than OCI Object Storage, including GitHub, Azure & AWS S3.
Pass a value for
logdirin theformatparameter to tell Oracle which directory to create the log and bad files. The default isDATA_PUMP_DIR.Pass a value for
logretentionin theformatparameter to tell Oracle how long you want the log and bad files/external tables to be kept. The default is 2 days.- You can also use
DBMS_CLOUD.DELETE_OPERATION(<operation_id>);to delete artifacts related to a specific copy, or useDBMS_CLOUD.DELETE_ALL_OPERATIONS;to delete all operations and related artifacts.
- You can also use
You can install the DBMS_CLOUD utilities on-premise by following this Oracle Support Note 'How To Setup And Use DBMS_CLOUD Package (Doc ID 2748362.1)', or this post.
Documentation for dbms_cloud.copy_data.
Documentation for format parameter options. I encourage you to review all of these options!
Conclusion
I hope you found this post useful. The dbms_cloud.copy_data PL/SQL API helps reduce the amount of code you have to write and can significantly improve performance over other methods for loading data.
🙏 Thanks
A big Thank You to Matt Paine for alerting me to this great utility and providing some excellent insights into what to watch out for when using it.
Also, many thanks to Sanket Jain from the Autonomous Database group for reaching out to me and correcting me on how dbms_cloud.copy_data works behind the scenes.