Two Methods for Batching Records with Oracle SQL
Introduction
It is not often that you need to split records into batches. When you do, however, having a couple of approaches to fall back on is helpful. In the past month, I encountered two problems requiring me to batch records using two approaches. This post will explain each of these approaches.
The NTILE Analytic Function. The NTILE function divides an ordered data set into equal buckets and assigns an appropriate bucket number to each row.
Using the
OFFSETandLIMITSQL (row limiting clause) to page through a data set.
The NTILE Approach
Over my career, I have had to batch records to simplify processing several times. Sometimes a set of records is just too big, and you need to break it down into manageable chunks.
One reason you may want to do this is so that each batch of records can be processed in parallel to speed up the overall processing time.
In the past, I may have written some complex PL/SQL logic to loop through the target table first, assigning batch numbers to each record before the primary processing is run. With the NTILE function, I can now do this much more quickly.
Let's take the following table called ev_sales_by_year. It contains records of EV sales in California:
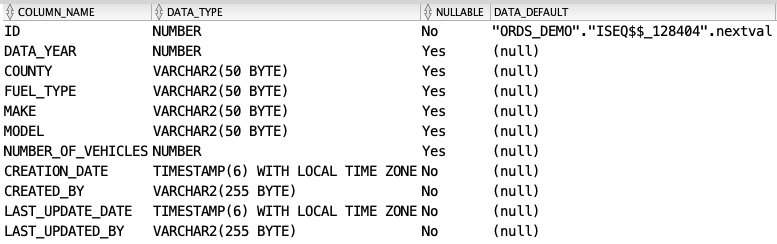
The table has 15,591 records, and I want to split it into about 5,000 records per batch. The NTILE function expects you to provide an Integer with the number of batches you want it to create. I first need to calculate the approximate number of batches we want based on a target batch size.
SELECT COUNT(1) total_row_count
, ROUND((COUNT(1) / 5000),0) number_of_batches
FROM ev_sales_by_year;
We are looking for a target batch size of 5,000 records in the above example. This results in the following:

Now that we know the number of batches (3), we can use the NTILE function to split the table into batches.
SELECT id
, NTILE(3) OVER (ORDER BY id) batch_number
FROM ev_sales_by_year;
This results in a list of every record in the table with its ID value and associated batch number.

This helps, but we can do better. Because I have a unique ID column in the table ev_sales_by_year, I can generate a list of batches with the minimum and maximum ID for each batch as follows:
SELECT batch_number
, MIN(id) min_id
, MAX(id) max_id
, COUNT(1) batch_size
FROM (SELECT id
, NTILE(3) OVER(ORDER BY id) batch_number
FROM ev_sales_by_year)
GROUP BY batch_number
ORDER BY batch_number;
ORDER BY a unique value/key to avoid overlapping IDs in each batch.This results in the following batches:
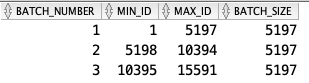
Now, I can loop through these three batches, pulling in each set of records using the MIN_ID and MAX_ID values.
-- Batch Number 1
SELECT *
FROM ev_sales_by_year
WHERE id BETWEEN 1 AND 5197;
Putting it all Together in PL/SQL
We can put this all together in a PL/SQL block as follows:
DECLARE
CURSOR cr_batches (cp_num_buckets IN PLS_INTEGER) IS
SELECT batch_number
, MIN(id) min_id
, MAX(id) max_id
, COUNT(1) batch_size
FROM (SELECT id
, NTILE(cp_num_buckets)
OVER (ORDER BY id) batch_number
FROM ev_sales_by_year)
GROUP BY batch_number
ORDER BY batch_number;
CURSOR cr_batch (cp_min_id IN NUMBER, cp_max_id IN NUMBER) IS
SELECT *
FROM ev_sales_by_year
WHERE id BETWEEN cp_min_id AND cp_max_id;
c_batch_size CONSTANT PLS_INTEGER := 5000;
l_num_buckets PLS_INTEGER;
BEGIN
-- Calculate the number of buckets based on our target batch size.
SELECT ROUND((COUNT(1) / c_batch_size),0) INTO l_num_buckets
FROM ev_sales_by_year;
-- Generate list of batches with Min and Max ID values.
FOR r_batch IN cr_batches (cp_num_buckets => l_num_buckets) LOOP
dbms_output.put_line('Bucket#: ' || r_batch.batch_number ||
' Min/Max ID: '|| r_batch.min_id ||
'/' || r_batch.max_id);
-- Do something with the batch.
FOR r_record IN cr_batch
(cp_min_id => r_batch.min_id,
cp_max_id => r_batch.max_id) LOOP
NULL;
END LOOP;
-- Something else you could do is launch a DBMS_SCHEDULER
-- job for each batch so they can be processed in parallel.
END LOOP;
END;
/
This results in the following:
Bucket#: 1 Min/Max ID: 1/5197
Bucket#: 2 Min/Max ID: 5198/10394
Bucket#: 3 Min/Max ID: 10395/15591
Of course, instead of just looping through the batches, it may be more useful to launch a DBMS Scheduler Job for each batch so that they can be processed in parallel.
Offset & Limit Approach
In this example, I want to export the content of the table ev_sales_by_year to JSON and then send the JSON to another system for processing. To make handling the JSON more manageable for the other system, I have split the export into several equally sized JSON files.
Sample Code
The code below illustrates how this can be achieved using the Row Limiting Clause in SQL.
I have included comments in the code to explain each step.
DECLARE
lc_rows_per_file CONSTANT PLS_INTEGER := 5000;
l_total_rows PLS_INTEGER;
l_offset_row PLS_INTEGER;
l_file_count NUMBER;
l_json_clob CLOB;
l_json_blob BLOB;
l_json_blob_zip BLOB;
BEGIN
-- Determine Number of Records in the Table.
SELECT COUNT(1) INTO l_total_rows
FROM ev_sales_by_year;
-- Calculate the number of JSON files to generate.
l_file_count := CEIL(l_total_rows / lc_rows_per_file);
dbms_output.put_line ('Generating ['|| TO_CHAR(l_file_count,'fm990') ||
'] files.');
-- Loop through generating a file for each set of 5,000 records.
FOR i IN 1..l_file_count LOOP
-- Calculate the Offset for the current interation.
l_offset_row := (i * lc_rows_per_file) - lc_rows_per_file;
-- Select a batch of 5,000 records starting at the current offset.
-- Note: the final batch may have less than 5,000 rows.
WITH file_rows AS
(SELECT *
FROM ev_sales_by_year
ORDER BY id
OFFSET l_offset_row ROWS
FETCH FIRST lc_rows_per_file ROWS ONLY)
SELECT json_object
('items' value json_arrayagg
(json_object (* ABSENT ON NULL RETURNING CLOB) RETURNING CLOB
) RETURNING CLOB)
INTO l_json_clob
FROM file_rows;
-- Note 1: The 'ABSENT ON NULL' clause omits NULL fields from the
-- JSON. This can significantly reduce the size of JSON files.
-- Note 2: The 'RETURNING CLOB' caluse is neccessary to when
-- generating large JSON CLOBs.
-- Convert the JSON CLOB to a BLOB.
l_json_blob := apex_util.clob_to_blob (p_clob => l_json_clob);
dbms_output.put_line ('JSON BLOB created, Size: '||
apex_string_util.to_display_filesize(dbms_lob.getlength(l_json_blob)));
-- Add the BLOB to a ZIP File.
apex_zip.add_file
(p_zipped_blob => l_json_blob_zip,
p_file_name => 'file_'||i||'.json',
p_content => l_json_blob);
END LOOP;
-- Close out the ZIP File.
apex_zip.finish (p_zipped_blob => l_json_blob_zip);
dbms_output.put_line ('ZIP File Size: '||
apex_string_util.to_display_filesize(dbms_lob.getlength(l_json_blob_zip)));
-- Now you can send the Zipped BLOB containing the 5 JSON
-- files to OCI Object Store, or any other target system.
END;
/
ORDER BY a unique value/key to avoid overlapping IDs in each batch.Output from the above script:
Generating [4] files.
JSON BLOB created, Size: 1.5MB
JSON BLOB created, Size: 1.5MB
JSON BLOB created, Size: 1.5MB
JSON BLOB created, Size: 180.2KB
ZIP File Size: 167.5KB
Bonus Approach
Of course, there are many ways to skin a cat. There is another approach I can think of (and I am sure there are more), which is to use BULK COLLECT to fetch batches of records into a PL/SQL array. Bulk collecting into PL/SQL arrays can be a very efficient way of processing large volumes of records in PL/SQL.
The example code below includes comments to explain what it does.
DECLARE
CURSOR cr_ev_sales IS
SELECT *
FROM ev_sales_by_year;
-- Declare a tebl type based on records from the table ev_sales_by_year
TYPE lt_ev_sales_t IS TABLE OF ev_sales_by_year%ROWTYPE INDEX BY PLS_INTEGER;
-- Dellare a PL/SQL table to store records.
lt_ev_sales lt_ev_sales_t;
-- Determine how many record to fetch during each iteration.
lc_fetch_count CONSTANT PLS_INTEGER := 5000;
l_total_vehicles NUMBER := 0;
BEGIN
-- Open the Cursor and Start Looping.
OPEN cr_ev_sales;
LOOP
-- Bulk collect 5,000 rows from the table into the PL/SQL
-- table lt_ev_sales.
FETCH cr_ev_sales
BULK COLLECT INTO lt_ev_sales LIMIT lc_fetch_count;
dbms_output.put_line ('Fetched ['||
TO_CHAR(lt_ev_sales.COUNT(),'fm999,999,990') || '] rows.');
-- Exit the loop when there are no more records to fetch.
EXIT WHEN lt_ev_sales.COUNT = 0;
-- Loop through the records in the PL/SQL table.
FOR i IN 1..lt_ev_sales.COUNT LOOP
-- Add code here to something with the rows in the PL/SQL table.
l_total_vehicles := l_total_vehicles +
lt_ev_sales(i).number_of_vehicles;
END LOOP;
END LOOP;
CLOSE cr_ev_sales;
dbms_output.put_line ('Grand Total Vehicles ['||
TO_CHAR(l_total_vehicles,'fm999,999,990') || '].');
END;
One of the advantages of this approach (other than its speed) is that you can limit the amount of memory used for the PL/SQL table. In the above example, we fetch at most 5,000 records at a time.
Conclusion
Hopefully, this post has shown you that although batching records into manageable chunks does not come up often, it is good to have several approaches that you can employ when it does.