AI SKILLS as a Thin Layer Over MCP Tools
Introduction
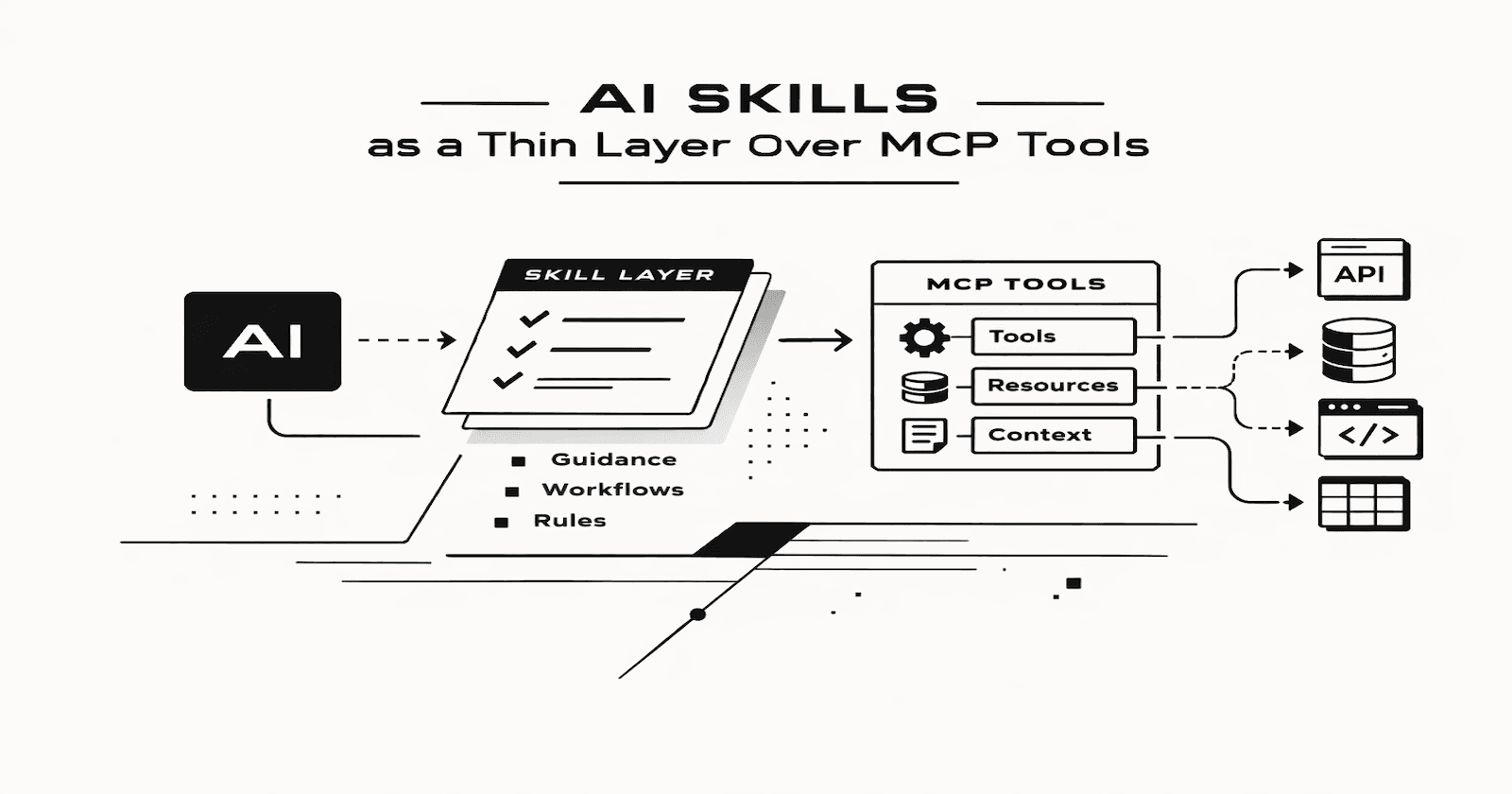
I have been experimenting with using AI Skills as a thin layer on top of MCP-backed tools, and I think this pattern is more useful than it first appears.
At a technical level, MCP gives the model standardized access to external tools and context. That is valuable, but raw tool access is not always enough. A model may know that a tool exists, but still needs guidance on when to use it, how to use it, what the tool is for, and what “good usage” looks like in the context of a specific prompt.
That is where I am finding Skills useful.
Rather than thinking of a Skill as replacing an MCP server, I think of it as a focused instructional layer on top of one or more MCP tools. The Skill captures intent, usage conventions, and domain-specific behavior. In practice, that makes tool use more reliable and reduces the amount of prompting I need to do each time.
$skill_name. MCP servers do not provide that same kind of direct user-facing invocation.An example with Oracle ORDS
To make this more practical, I built a small STDIO MCP server that exposes an Oracle ORDS REST web service on a table called JD_SB_ENTRIES. This table stores records in a second brain app. By “second brain,” I mean the usual personal knowledge tasks: capturing notes, storing ideas, tracking follow-ups, organizing knowledge, and retrieving things later in a structured way.
The ORDS side is straightforward. I registered a template for the table with handlers for GET, POST, PUT, and DELETE that map to CRUD database operations. I secured the ORDS module that the template was created in using an OAuth 2.0 client.
ORDS.ENABLE_OBJECT to Auto-REST enable the JD_SB_ENTRIES table. This generates the entire CRUD API instantly, allowing you to focus entirely on the MCP/Skill interaction layer rather than writing PL/SQL backend handlers.I built an STDIO MCP Server in Python using the Codex desktop app. STDIO MCP servers run locally on your machine. The MCP server then exposes the REST APIs to the model through a tool interface.
The model can use the MCP tool to create, read, update, and delete rows through ORDS, without needing to know the low-level details of the HTTP call each time.
It works.
But I soon found that getting the MCP server to act on my prompts was erratic (at best). I also have Office 365 linked to my Codex desktop app setup, so the model would often choose Microsoft Planner over my tool. It would also conflict with Office 365 Calendar. It's understandable, really.
A request like "add a task for tomorrow to clean the car" would make sense for MS Outlook just as much as for my second brain.
This confusion from the LLM occurs despite clear instructions in the MCP server services definition on how to use the tool.
YAML for the MCP Server Services
oauth:
token_url: https://example.adb.us-chicago-1.oraclecloudapps.com/ords/demo/oauth/token
scopes: ""
services:
- id: jd_sb_entries
name: JD Second Brain Tasks, Notes, and Reminders
base_url: https://example.adb.us-chicago-1.oraclecloudapps.com/ords/demo/mcp/
description: "Manage second-brain entries from natural user requests. Use this service when the user wants to add, create, save, list, review, update, or delete notes, tasks, ideas, knowledge entries, or reminder-style entries with a due date. Create new entries at jd_sb_entries and update or delete existing entries at jd_sb_entries/{entry_id}. This stores reminders as second-brain tasks or notes; it does not create real Planner or calendar reminders. Infer the correct action from conversational requests whenever possible."
default_headers:
Accept: application/json
timeout_seconds: 30
pagination:
default_page_size: 100
max_page_size: 250
max_pages_per_call: 10
max_items_per_call: 500
examples:
- "Use rest_mcp_server to add a todo for tomorrow: clean car."
- Add a new task reminding me to review the ORDS spec tomorrow.
- Save a reminder for tomorrow to review the ORDS spec.
- Create a note about MCP server pagination and save the full details.
- "Add this to my second brain: review the ORDS spec tomorrow."
- Show me my second-brain entries.
- Update entry 123 to mark it high urgency.
- Delete entry 456.
columns:
- name: entry_id
data_type: NUMBER
nullable: false
writable: false
description: Primary key identity column.
- name: subject
data_type: VARCHAR2(255)
nullable: false
writable: true
description: Short subject line.
- name: entry_type
data_type: VARCHAR2(30)
nullable: false
writable: true
description: Entry classification.
enum_values:
- IDEA
- TASK
- NOTE
- KNOWLEDGE
- name: ai_summary
data_type: VARCHAR2(32767)
nullable: false
writable: true
description: AI-generated summary.
- name: user_content
data_type: CLOB
nullable: false
writable: true
description: Full entry body.
- name: urgency
data_type: VARCHAR2(30)
nullable: true
writable: true
description: Optional urgency.
enum_values:
- LOW
- MEDIUM
- HIGH
- name: action_required
data_type: VARCHAR2(1)
nullable: false
writable: true
description: Whether action is required.
enum_values:
- Y
- N
- name: due_date
data_type: DATE
nullable: true
writable: true
description: Optional due date in YYYY-MM-DD format.
The model still needs to understand what the API represents in business terms, how it should behave when used, and which requests should trigger a call. A generic CRUD interface is flexible, but also vague.
Using a Skill for a second brain workflow
To counter this vagueness, I decided to create a skill focused specifically on the second brain ORDS API.
Agent Skills are folders of instructions, scripts, and resources that agents can discover and use to do things more accurately and efficiently.
This turned out to be more useful than I expected.
The Skill did three important things.
1. It guided the use of the REST API
The MCP tool exposed the API's mechanics. The Skill explained how to use it.
That distinction matters.
The tool knew how to call the endpoint. The Skill told the model when to create a note, when to update an existing item rather than insert a new one, which fields mattered, and how to interpret user requests in the context of a second brain.
Without that layer, the model has to infer too much from the tool signature and endpoint description. Sometimes that works. Sometimes it does not. The more domain-specific the workflow becomes, the more that gap shows up.
In practice, the Skill reduced a lot of that ambiguity.
2. It documented second brain functionality
The Skill also became a compact form of documentation.
Instead of only documenting the REST API as a technical interface, the Skill documented the behavior around the API. It explained what the second brain supports, the kinds of operations it is intended for, and the conventions the model should follow.
That is useful for the model and for me.
It gave me a single place to describe the intended workflow in practical terms rather than just API terms. In other words, it documented capability, not just transport.
I think this is an underrated part of Skills. They are not only prompt helpers. They can also serve as executable documentation for an AI-facing workflow.
3. It allowed explicit invocation with $skill
This was the third benefit, and in some ways, the most practical.
Because the behavior was packaged as a Skill, I could explicitly invoke it with $skill_name.
That gave me a clean way to direct the model toward a very specific behavior package. I was not just hoping the model would choose the right MCP tool based on a vague request. I could point it at the exact Skill that I knew would work with that second brain API.
That explicit invocation made the interaction more predictable.
SKILL.md
---
name: "second-brain"
description: "Use when the user wants to add, update, list, or delete second-brain notes, tasks, ideas, knowledge items, or reminder-style entries through the local rest-mcp server. Prefer this skill when the user explicitly says $second-brain."
---
Second Brain
Use this skill for second-brain CRUD work through the local rest-mcp MCP server.
Core Rules
- Use
service_id: "jd_sb_entries".
- Use
path: "jd_sb_entries" for create and list. Use path: "jd_sb_entries/{entry_id}" for a specific row.
- For filtered
GET requests, use ORDS q filter syntax, not ad hoc column query params.
- Preferred form: pass
query as a native object and pass query.q as a native object. The MCP server will JSON-encode q.
- Accepted alternate form: pass
query as a raw query string such as q={"entry_type":{"$eq":"TASK"}}&limit=25.
- Do not send second-brain filters as top-level keys like
"entry_type": "TASK" unless the service explicitly documents that parameter.
- For structured arguments, verify
body and headers are native objects before calling the tool. For query, prefer a native object unless a raw query string is more direct.
- Use
page_limit and item_limit for pagination.
- If fields, enum values, or filter keys are unclear, call
rest-mcp.describe_service once. Do not retry blindly with alternate query formats.
- Use ORDS operators inside
q as needed: \(eq, \)ne, \(instr, \)like, \(gte, \)lte, \(or, \)and.
- Keep list results compact and results-focused.
- Never paste raw MCP response JSON into the user-facing reply. Extract the needed fields and summarize.
Fixed Playbooks
- If the user asks to show, list, pull, or review active todos/tasks/reminders, make exactly one
GET call with:
{
"service_id": "jd_sb_entries",
"method": "GET",
"path": "jd_sb_entries",
"query": {
"q": {
"entry_type": {
"$eq": "TASK"
},
"action_required": {
"$eq": "Y"
}
}
},
"page_limit": "1",
"item_limit": "25"
}
- For that active-task flow, do not probe with alternative query formats, do not call
describe_service, and do not say "retrying" unless an unexpected runtime error actually occurred.
- After fetching active tasks, sort by
due_date ascending before replying unless the user asks for a different order.
- Reply with only the compact task list:
#entry_id subject — due YYYY-MM-DD.
Batch Rules
- Default to single-item mode.
- Enter batch mode only when the user clearly asks for multiple items or refers to a concrete earlier list.
- For prior-thread items, restate a compact working list in the current turn before writing.
- If the earlier items are missing or ambiguous, ask the user to narrow the scope or restate them.
- Process at most 5 items per turn unless the user explicitly asks for more.
- Create or update sequentially, one
request_resource call per item.
- If a batch partially succeeds, report completed items and the first failure clearly.
Field Mapping
todo, task, reminder -> entry_type: "TASK"note -> entry_type: "NOTE"idea -> entry_type: "IDEA"knowledge -> entry_type: "KNOWLEDGE"- For todos/reminders, default
action_required to "Y".
- Default
urgency to "LOW" unless the user says otherwise.
- Use title case for
subject unless the user specifies exact casing.
- Use the raw user text or a slightly cleaned version for
user_content.
- Create a short
ai_summary from the request.
- Convert relative dates like
tomorrow into an absolute YYYY-MM-DD date using the user's locale timezone.
- Treat returned
due_date values as ISO timestamps and present them back to the user as dates when only the date matters.
Request Patterns
Create:
{
"service_id": "jd_sb_entries",
"method": "POST",
"path": "jd_sb_entries",
"body": {
"subject": "Clean car",
"entry_type": "TASK",
"ai_summary": "Reminder to clean the car tomorrow.",
"user_content": "clean car",
"urgency": "LOW",
"action_required": "Y",
"due_date": "2026-03-15"
}
}
List active tasks:
{
"service_id": "jd_sb_entries",
"method": "GET",
"path": "jd_sb_entries",
"query": {
"q": {
"entry_type": {
"$eq": "TASK"
},
"action_required": {
"$eq": "Y"
}
}
},
"page_limit": "1",
"item_limit": "25"
}
Search for entries containing a phrase:
{
"service_id": "jd_sb_entries",
"method": "GET",
"path": "jd_sb_entries",
"query": {
"q": {
"$or": [
{
"subject": {
"$instr": "ORDS"
}
},
{
"user_content": {
"$instr": "ORDS"
}
}
]
}
},
"page_limit": "1",
"item_limit": "25"
}
Read one row:
{
"service_id": "jd_sb_entries",
"method": "GET",
"path": "jd_sb_entries/32"
}
Bad query examples:
"query": {
"entry_type": "TASK",
"action_required": "Y"
}
"query": "{\"entry_type\":{\"$eq\":\"TASK\"}}"
Good raw query-string example:
"query": "q={\"entry_type\":{\"\(eq\":\"TASK\"},\"action_required\":{\"\)eq\":\"Y\"}}&limit=25"
Response Style
- For simple creates, reply with the created
entry_id, subject, and due date.
- For list/read requests, return the concise result only. Do not echo tool payloads, headers, links, or pagination blobs.
- Keep the response short.
- If the request is ambiguous, ask one concise clarifying question.
Demo
This recording shows a brief interaction with my 2nd brain after introducing the skill.

Why this pattern matters
The broader point is that MCP and Skills solve different problems.
I like this analogy from the Anthropic "The Complete Guide to Building Skills for Claude".
The kitchen analogy.
MCP provides the professional kitchen: access to tools, ingredients, and equipment. Skills provide the recipes: step-by-step instructions on how to create something valuable.
If you only expose a tool, you are giving the model capability. If you add a Skill, you are giving it operating guidance. For simple tools, that extra layer may not matter much. For anything with workflow, conventions, or domain context, it matters a lot.
That is why I think Skills work well as a thin layer on top of MCP-backed tools.
They do not replace the server.
They do not replace the API.
They do not replace good tool design.
What they do is close the gap between “the model can call this” and “the model knows how this should be used here.”
Conclusion
A lot of MCP discussions focus on exposing tools, which makes sense. But once you start building real workflows, raw tool exposure is only the starting point. You also need a way to shape behavior around those tools.
For me, Skills are proving to be a good way to do that.
In this case, a simple STDIO MCP server exposed ORDS REST APIs for CRUD operations on a table. The Skill sitting on top of one of those APIs made the setup much more usable by guiding the workflow, documenting the behavior, and providing an explicit invocation surface via $skill.
That is a small design choice, but it has made the overall system feel much more intentional.