AI Hygiene for APEX Developers
Managing Conflicting Instructions in APEX Projects
Introduction
AI-assisted development for Oracle APEX work is moving beyond one-off prompts and into something much more structured.
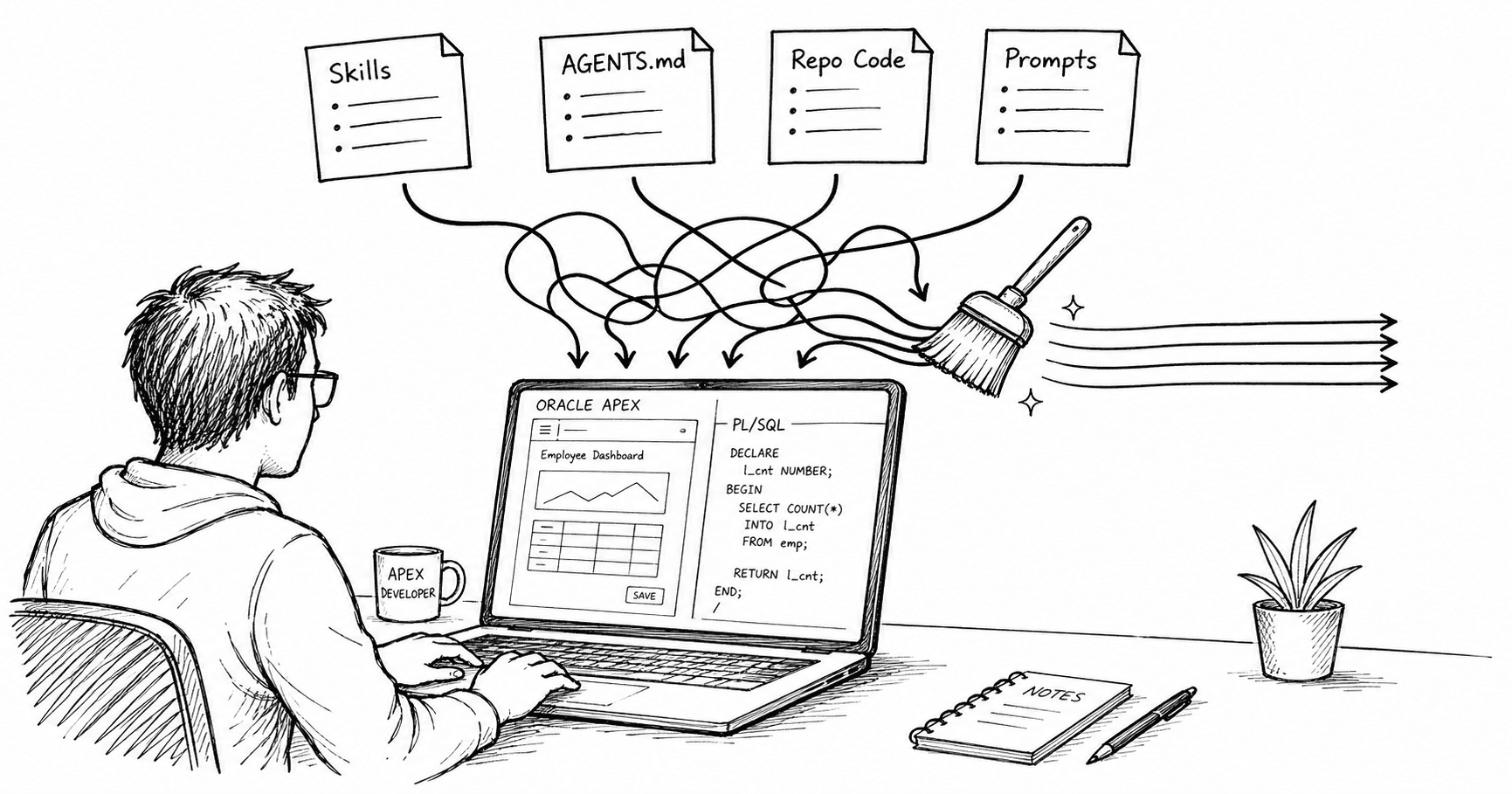
We now have reusable skills, repo-level instruction files, agent configuration, project standards, prompt libraries, and more detailed tooling around code generation and review. That is useful. It also creates a new problem: your AI context can get messy very quickly.
In this post, I want to look at what I mean by AI hygiene, why it matters for APEX and PL/SQL developers, and where I have already seen it go wrong.
What I Mean by AI Hygiene
When I say AI hygiene, I mean keeping the instruction layer around the model clean, up to date, and free of conflicts.
For Oracle developers, that instruction layer can include:
Oracle-provided skills: oracle-skills and APEXlang skills (when they are released)
community-developed skills
your own PL/SQL or APEX skills
CLAUDE.mdorAGENTS.mdcode that is already in the repo
repo README files
MCP tool descriptions
prompt libraries
That is a lot of context for a model to reconcile. If those sources line up, the results can be very good. If they do not, the model will often produce something that looks plausible, compiles cleanly, and still doesn't do what you want it to.
That is why I think of AI hygiene as code hygiene for the instruction layer.
Reducing unnecessary or conflicting context can lower token usage (and therefore cost) and improve time to first token, especially as tools, skills, and repo guidance accumulate.
Why This Matters More for Oracle Work
Oracle development is unusually context-sensitive.
A decent answer is not just about knowing PL/SQL syntax or APEX component names. It also depends on version compatibility, security patterns, naming conventions, package structure, logging standards, deployment rules, and sometimes very specific local constraints around ORDS, APIs, and the database architecture.
For example, a generic Oracle skill might reasonably recommend things like:
use packages for reusable business logic
avoid dynamic SQL where possible
prefer bind variables
use clear exception handling
account for version-specific syntax
None of that is wrong. The problem is that your project may also require:
all business logic to go through package APIs
no core logic in APEX page processes
a specific logging package or wrapper
compatibility with Oracle Database 19c
compatibility with a specific APEX version until a future upgrade is complete
At that point, the question is no longer, "Is the model good at Oracle?" The real question is, "Which instruction wins?"
The Problem Is Not Bad Syntax
When people worry about AI-generated code, they often focus on whether it compiles. That is a fair concern, but it is not the one I worry about most. The more dangerous failure mode is plausible wrongness. In other words, code that is technically valid but wrong for your application.
That can look like:
valid PL/SQL in the wrong package
valid SQL that ignores tenant isolation
valid APEX page logic placed in the wrong layer
valid ORDS handlers with the wrong response structure
valid exception handling that hides errors
In practice, that kind of output is more dangerous than obvious AI slop because it creates both review overhead and false confidence.
Where I Saw This Happen
One of the clearest examples I have seen was with a PL/SQL-focused skill I was using while developing APEX applications.
The skill itself was helpful. It pushed the model toward better package structure, cleaner SQL, stronger exception handling, and more Oracle-aware output. On its own, that was a net positive.
The issue was that I also had AGENTS.md files sitting in individual repositories, which had grown organically over time. Some predated AI skills entirely. Some reflected older project conventions. Some made sense for one app but not another. Some were simply too broad.
So I had two different instruction sources operating at once:
the skill was trying to enforce general Oracle and PL/SQL best practices
the repo-level
AGENTS.mdfiles were trying to enforce local architecture and workflow rules
That sounds fine until those two sources disagree.
I would get output that mixed conventions:
package structure from the skill
naming from the repo file
exception handling from an old example
architecture decisions from whichever instruction happened to dominate in that run
Nothing about that output was obviously broken. That was the problem. It was technically reasonable code, but it still required cleanup because the instruction environment was dirty. That kind of issue becomes more common as we add more reusable AI context, not less.
Why APEX Makes This Even More Interesting
This becomes even more relevant for APEX developers when APEX 26.1 (and APEXlang) is released, enabling us to use AI to generate APEX applications.
Once your application structure, component metadata, and declarative configuration are more accessible to AI-driven workflows, the upside is obvious. You can imagine better review tooling, better automation, better generation, and better assistance around large APEX applications.
However, that also increases the number of instruction surfaces that can conflict.
For example, you may end up balancing:
a general Oracle skill
an APEX-specific skill
project architecture rules
UI conventions
security constraints
task-specific prompts
That is exactly why AI hygiene matters. The more an AI can touch, the more important it becomes to control the rules that guide those changes.
A Better Mental Model: Instruction Layers
The cleanest way I have found to think about this is to separate instruction authority from repository reality.
Some things are explicit instructions. Some are evidence of how the application actually works today. Those are not the same, and treating them as the same is where much of the confusion starts.
Instruction Authority
Vendor or ecosystem skills
|
v
Internal reusable skills
and community skills
|
v
AGENTS.md
|
v
Task prompt
Reality check
Existing repository code
(current implementation)
1. Vendor or Ecosystem Skills
These provide broad technology competence.
This is where I would want Oracle-focused guidance, SQL and PL/SQL best practices, documentation-backed patterns, and general platform knowledge to live.
These skills should make the model better at Oracle. They should not try to encode every project-specific convention you have.
This includes Oracle-provided skills when they exist, but I would not automatically assume vendor-provided skills are more authoritative than a well-maintained internal skill. The real distinction is between broad platform knowledge and local rules.
2. Internal Reusable Skills and Community Skills
This is where your own reusable skills and outside community skills usually sit.
For example, this layer may include:
internal APEX architecture patterns
shared package templates
organization-specific API conventions
approved approaches for ORDS, JSON, or security wrappers
coding, logging, security, or naming standards reused across repositories
This is often the most important layer in practice because it bridges the gap between general Oracle competence and the needs of a real delivery team.
3. Project or Repository Instructions
This is where CLAUDE.md or AGENTS.md sits. The job of this layer is to explain how this specific application works:
project context
project naming conventions
technology versions (APEX 26.1, Oracle DB 19c, etc.)
project-specific architecture rules
testing and deployment expectations
approved exceptions to broader standards
This file should not become a junk drawer for every Oracle best practice you have ever liked.
Ideally, your AGENTS.md should be less than a dozen bullet points. The bulk of the instructions should come from skills that can be reused for all of your projects.
4. Existing Repository Code
This is not just another instruction file. It is an implementation reality.
The codebase shows:
what patterns are actually in use
what package boundaries already exist
what naming is really present
what versions and compatibility assumptions the project appears to follow
where the written instructions may already be stale
If AGENTS.md says one thing and the repository consistently does another, that is not a simple question of precedence. It is a hygiene problem that needs to be resolved deliberately.
Vendor skills should teach the model the platform. Internal reusable skills should teach your conventions. AGENTS.md should teach the project. The codebase should teach reality.
5. Task Prompt
This is the immediate ask:
review this package
generate this API
refactor this page process
propose an APEX app structure
The prompt should clearly describe the job, but it should not be forced to restate everything already in the higher layers.
The rule I would use is simple:
Put instructions at the lowest stable layer where they belong.
And when written instructions conflict with the existing codebase, stop pretending the hierarchy is clean. That is the moment to decide whether the code needs refactoring or the instructions need updating.
Common Sources of AI Context Rot
Once you start looking for it, instruction drift shows up everywhere.
The usual problems are:
stale
AGENTS.mdfiles that describe an older architectureolder examples that teach the model outdated patterns
duplicated rules spread across skills, READMEs, and agent files
version assumptions that no longer match production reality
copied prompt fragments nobody wants to delete
unclear authority between skill guidance and repo guidance
Typically, the worst cases are not dramatic. They are subtle. You just start seeing output that feels slightly off. The model is not exactly wrong, but it is clearly pulling from incompatible instructions.
A Checklist for Better AI Hygiene
If you want to improve this without turning it into a process nightmare, I would start with a short checklist.
Inventory your instruction sources
List every place your AI tooling can pull guidance from:
skills
AGENTS.mdREADME files
coding standards
templates
prompt libraries
examples
existing code
Decide what wins
For each category, define the default source of truth and what counts as the reality check.
For example:
PL/SQL style usually comes from internal reusable skills or shared templates
generic Oracle best practice comes from a vendor, ecosystem, or internal skill
cross-project architecture conventions come from your own reusable skills
project-specific knowledge, software versions, and local constraints come from
AGENTS.mdoutput formatting comes from the task prompt
If you do not define authority, the model will improvise it for you. If you do not check that authority against the current codebase, you will miss drift.
Search for conflict words
Look for words like:
always
never
must
avoid
required
deprecated
version
exception
security
logging
Those words tend to reveal hidden conflicts very quickly.
In an APEX repo, a quick example is a project rule that says all business logic must live behind packaged APIs while the prompt or a reusable skill keeps generating logic directly in page processes. Both outputs may be valid. Only one matches the architecture.
Remove duplicate rules
If the same instruction exists in five places, it will eventually drift.
I would rather have:
a skill that provides broad Oracle guidance
an internal reusable skill or shared template that defines mandatory patterns
a repo file that only documents local exceptions and architecture
That is much easier to maintain.
Test your instruction stack
This is the part I think many people will skip, and they should not.
Use a few repeatable prompts such as:
generate a package for expense approval logic
review this APEX page process for security issues
create an ORDS GET handler for employee expenses
write SQL compatible with Oracle Database 19c
Then check whether the output actually follows your standards.
If the same prompt produces different architectural decisions depending on which repo you run it in, you probably have an AI hygiene problem.
Conclusion
AI-assisted Oracle development is not just about better models and better prompts anymore. It is also about managing the instruction environment around the model.
That means skills, standards, repo rules, examples, and prompts all need to work together rather than compete for control. I have already seen how a useful PL/SQL skill can become less useful when it collides with inconsistent AGENTS.md files spread across repositories. The model was not the weak link there. My instruction layer was.
As Oracle-focused skills become more common and AI-driven workflows become more practical for APEX and PL/SQL teams, I think this only gets more important.
Your instructions are no longer just notes for the model. They are part of your development environment now, and they deserve to be maintained with the same care as code.