APEX Developer Blogs Website

Introduction
In 2023, I announced the launch of the ➡️ APEX Developer Blogs ⬅️ Website. This website aggregates blog posts with content relevant to Oracle APEX Developers and provides a one-stop shop for searching and subscribing to blog posts related to Oracle APEX Development.
This post will provide insights into the tech behind the website and some of the features of APEX & ORDS that made it possible.
Onboarding New Blogs
The app allows users to register their blog easily:
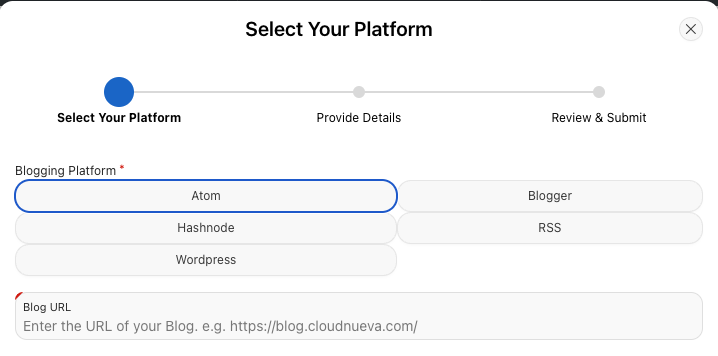
The user is taken through a simple Wizard, where they select their blogging platform and enter a few details about their blog. The App calls the feed related to the blog to default the Blog Name and Author (see below). Once registered, the blog is added to the blogs table in a Pending status. I get notified and can elect to accept the blog (assuming it is relevant to APEX Developers).
The method for obtaining the blog author, title, etc, from the Blog differs based on the platform.
Hashnode

Hashnode is a modern, easy-to-use blogging platform. It also provides a comprehensive Graph API, which was recently re-vamped and provides unprecedented ease of access to all of the blogs hosted by Hashnode.
The following code shows how I call the Hashnode API to get details about a specific blog. I start by declaring a constant in the PL/SQL package with JSON that fetches information about a Publication on Hashnode. The constant includes a substitution variable #HOSTNAME#, which I can later replace with the actual publication URL.
-- Constant with
GC_PUB_QUERY CONSTANT VARCHAR2(32000) := q'#
{"query":"query Publication {\n publication(host:\"#HOSTNAME#\") {\n id,\n title,\n descriptionSEO,\n url,\n author{name, profilePicture},\n displayTitle \n} \n}","variables":{}}
#';
Then, I call a function that substitutes #HOSTNAME# with the Blog URL provided by the user, call the Hashnode API using APEX_WEB_SERVICE, and parse the response. JSON_TABLE offers us a quick and easy method for parsing the response.
FUNCTION hashnode_publication (p_blog_url IN VARCHAR2)
RETURN cnba_blogs%ROWTYPE IS
l_pub_response CLOB;
l_pub_query VARCHAR2(32000);
lr_blog cnba_blogs%ROWTYPE;
l_domain VARCHAR2(100);
BEGIN
-- Extract the Domain for the Blog.
l_domain := apex_string_util.get_domain (p_blog_url);
-- Replace the #HOSTNAME# part of the payload with the domain.
l_pub_query := REPLACE(GC_PUB_QUERY, '#HOSTNAME#', l_domain);
-- Call the Hasnode API.
l_pub_response := apex_web_service.make_rest_request
(p_url => 'https://gql.hashnode.com/',
p_http_method => 'POST',
p_body => l_pub_query);
IF apex_web_service.g_status_code <> 200 THEN
raise_application_error (-20001, 'Error Fetching Hashnode Publication');
END IF;
-- Parse the Response from Hashnode and Populate a PL/SQL record
-- with details of the Blog.
BEGIN
SELECT jt.title
, jt.url
, jt.author
, jt.author_pic
, COALESCE(jt.display_title, jt.description_seo, 'No Description')
INTO lr_blog.title
, lr_blog.blog_url
, lr_blog.blog_owner
, lr_blog.avatar_url
, lr_blog.description
FROM JSON_TABLE(l_pub_response, '$.data.publication'
COLUMNS (title VARCHAR2(500) PATH '$.title',
url VARCHAR2(500) PATH '$.url',
author VARCHAR2(500) PATH '$.author.name',
author_pic VARCHAR2(500) PATH '$.author.profilePicture',
display_title VARCHAR2(4000) PATH '$.displayTitle',
description_seo VARCHAR2(4000) PATH '$.descriptionSEO'
)) jt;
EXCEPTION WHEN OTHERS THEN
raise_application_error (-20000, 'This does not seem to be a Hashnode Blog. Please double check your platform and the URL.');
END;
-- Return the record type with details about the Blog.
RETURN lr_blog;
END hashnode_publication;
As you can see from the code above, several useful APEX PL/SQL APIs like apex_string_util and apex_web_service, together with native JSON parsing with JSON_TABLE make this process easy.
RSS/Atom/WordPress/Blogger

All other blogging platforms utilize some kind of RSS or Atom Feed. This forces us to take a trip back to the world of XML parsing 😱.
The scripts below show how I extract the Blog title, description, etc., for these other blogging platforms using XMLTABLE to parse the XML response and APEX_WEB_SERVICE to get the content of the Blog feed.
-- RSS, Blogger, Wordpress
SELECT bl.*
FROM XMLTABLE(XMLNAMESPACES('http://purl.org/dc/elements/1.1/' AS "dc"), '/*/channel'
PASSING XMLTYPE(apex_web_service.make_rest_request(p_url => :BLOG_URL, p_http_method => 'GET'))
COLUMNS
last_build_date VARCHAR2(50) path 'lastBuildDate',
last_build_date2 VARCHAR2(50) path 'pubDate',
language_code VARCHAR2(10) path 'language',
language_code2 VARCHAR2(10) path 'dc:language',
generator VARCHAR2(50) path 'generator',
title VARCHAR2(500) path 'title',
blog_link VARCHAR2(500) path 'link',
description VARCHAR2(500) path 'description',
image_url VARCHAR2(500) path 'image/url'
) bl;
-- Atom
SELECT bl.*
FROM XMLTABLE( XMLNAMESPACES('http://www.w3.org/2005/Atom' AS "ns0"), 'ns0:feed'
PASSING XMLTYPE(apex_web_service.make_rest_request(p_url => :BLOG_URL, p_http_method => 'GET'))
COLUMNS
title VARCHAR2(255) PATH 'ns0:title',
description VARCHAR2(500) PATH 'ns0:subtitle',
generator VARCHAR2(500) PATH 'ns0:generator'
) bl;
Processing New Blog Posts
Once a blog is registered, I have an APEX Automation scheduled to run every evening. This fetches any newly published blog posts. The diagram below illustrates how this is done.
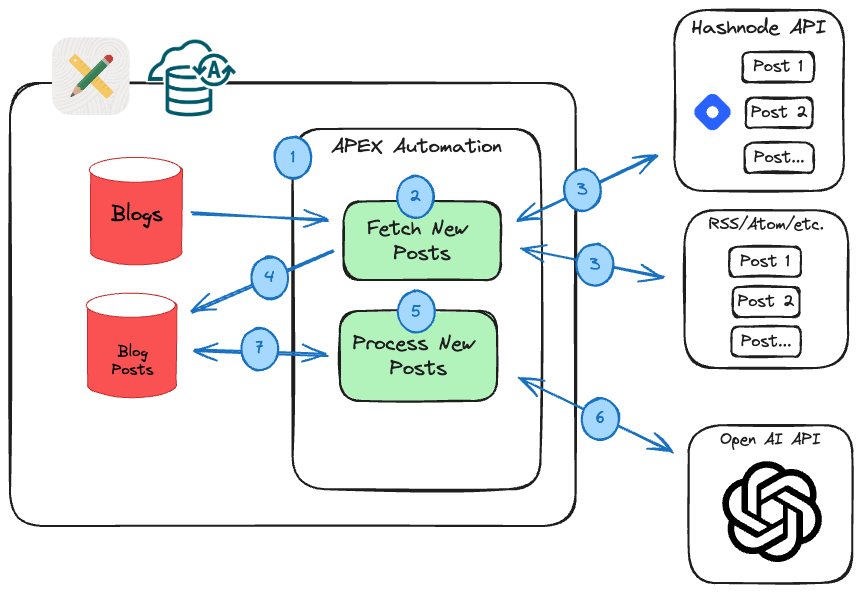
An APEX Automation runs every evening. The automation loops through all active blogs.
The APEX Automation checks for new blog posts not already in the database for each active blog.
For Hashnode, I call the Hashnode API again. The Hashnode API makes searching for and fetching the content of blog posts a breeze 🍃. Fetching the content of XML-based platforms like RSS and Atom is more challenging (more on this below).
Any new blog posts are added to a table in the Oracle database.
Once all the new posts have been captured, the Automation performs post-processing on each post. This involves calculating a word count, calculating reading time, generating a plain text version of the post (stripping HTML), etc.
Finally, I call Chat GPT, passing the first 4,000 characters of the post along with a prompt asking Chat GPT to determine if the new post is relevant to Oracle APEX Developer (more on this below).
If Chat GPT deems the new post irrelevant to Oracle APEX Developers, then the post is marked as excluded. Excluded posts are not indexed and do not show up on the APEX Developer Blogs App.
Fetching Blog Posts
Like blogs, fetching blog posts differs based on the platform.
Hashnode Posts
The Hashnode APIs make fetching blog posts easier and provide a richer dataset. To call the Hashnode APIs from PL/SQL, I follow a similar approach as I do for Blogs. I create constants that contain a template for the Graph QL query I want to execute and then substitute the actual value just before I call the Hashnode APIs.
At a high level, my code does the following:
Query the feed from the Blog and return just the post URL and Slug. This returns posts from the blog, starting with the latest.
I check to see if I have each post in the feed in the database. If I do not have the post, I query a second Hashnode API to get the post content.
As soon as I encounter a post that I have in my DB, I stop processing the feed.
This approach means I don't have to return the entire blog content until I know I need it. It also means that most times when I check the feed, I already have the first post in the local DB, so I can stop processing immediately. This makes processing the Hashnode API very fast.
I use the JSON below as a template for Querying a Blog's feed (GC_HN_FEED_QUERY) and then getting the blog's content (GC_HN_POST_QUERY).
GC_HN_FEED_QUERY CONSTANT VARCHAR2(32000) := q'#
{"query":"query Publication {\n publication(host:\"#HOSTNAME#\") {\n posts (first: 20 #AFTER#){\n edges{\n node {\n title,\n slug\n }\n }\n pageInfo {\n endCursor\n hasNextPage\n }\n }\n }\n}","variables":{}}
#';
GC_HN_POST_QUERY CONSTANT VARCHAR2(32000) := q'#
{"query":"query Publication {\n publication(host:\"#HOSTNAME#\") {\n post (slug:\"#SLUG#\"){\n url,\n coverImage {url},\n author{name}, \n brief,\n readTimeInMinutes,\n publishedAt,\n content {html,text}\n }\n }\n}","variables":{}}
#';
RSS/Atom/WordPress/Blogger Posts
All of these platforms return a similar but slightly different XML feed (don't get me started on standards). This section lists the SQL statements I use to process blog posts from these platforms.
-- RSS Feed
SELECT ai.*
FROM xmltable( XMLNAMESPACES('http://purl.org/dc/elements/1.1/' AS "dc"), '/*/channel/item'
PASSING XMLTYPE(apex_web_service.make_rest_request(p_url => :BLOG_URL, p_http_method => 'GET'))
COLUMNS
guid VARCHAR2(500) path 'guid',
date_published VARCHAR2(500) path 'pubDate',
title VARCHAR2(500) path 'title',
creator VARCHAR2(255) path 'dc:creator',
author VARCHAR2(255) path 'author',
link VARCHAR2(500) path 'link',
description CLOB path 'description',
cover_image VARCHAR2(500) path 'cover_image'
) ai;
-- Atom Feed
SELECT TO_UTC_TIMESTAMP_TZ(bp.date_published) date_published
, TO_UTC_TIMESTAMP_TZ(bp.date_updated) date_updated
, bp.guid
, bp.title
, bp.author
, NVL(bp.link, bp.link_alt) link
, bp.description
, bp.content
FROM XMLTABLE(XMLNAMESPACES('http://www.w3.org/2005/Atom' AS "ns0"), 'ns0:feed/ns0:entry'
PASSING XMLTYPE(apex_web_service.make_rest_request(p_url => :BLOG_URL, p_http_method => 'GET'))
COLUMNS
guid VARCHAR2(255) PATH 'ns0:id',
date_published VARCHAR2(50) PATH 'ns0:published',
date_updated VARCHAR2(50) PATH 'ns0:updated',
title VARCHAR2(500) path 'ns0:title',
author VARCHAR2(255) path 'ns0:author/ns0:name',
link VARCHAR2(500) path 'ns0:link[@rel eq "alternate"]/@href',
link_alt VARCHAR2(500) path 'ns0:link[1]/@href',
description VARCHAR2(500) path 'ns0:summary',
content CLOB path 'ns0:content'
) bp
-- Blogger Feed
SELECT ai.*
FROM xmltable('/*/channel/item'
PASSING XMLTYPE(apex_web_service.make_rest_request(p_url => :BLOG_URL, p_http_method => 'GET'))
COLUMNS
guid VARCHAR2(500) path 'guid',
date_published VARCHAR2(500) path 'pubDate',
title VARCHAR2(500) path 'title',
author VARCHAR2(255) path 'author',
link VARCHAR2(500) path 'link',
description CLOB path 'description',
cover_image VARCHAR2(500) path 'cover_image'
) ai;
-- Wordpress Feed
SELECT ai.*
FROM xmltable( XMLNAMESPACES('http://purl.org/dc/elements/1.1/' AS "dc", 'http://purl.org/rss/1.0/modules/content/' AS "content"), '/*/channel/item'
PASSING XMLTYPE(apex_web_service.make_rest_request(p_url => :BLOG_URL, p_http_method => 'GET'))
COLUMNS
guid VARCHAR2(500) path 'guid',
creator VARCHAR2(255) path 'dc:creator',
date_published VARCHAR2(500) path 'pubDate',
title VARCHAR2(500) path 'title',
link VARCHAR2(500) path 'link',
content CLOB path 'content:encoded'
) ai;
Using Chat GPT to Assess Relevance
One problem I have is that, occasionally, people like to post about things not directly related to their blog. Don't get me wrong, I think this is great, and I encourage everyone to step outside their comfort zone.
Previously, I did this manually. I would log in to an Admin App every few days and mark posts as excluded. This moved them to another table and excluded them from the Website and search. I recently introduced code to call an Open AI Completions API to assess the post's relevance to Oracle APEX Developers.
JSON Mode
Introducing Open AI calls into your code relies on your ability to parse and interpret the response into specific fields. This is made possible using JSON Mode when calling the Open AI API. This forces the API to return JSON. If you craft your prompt carefully, you can get JSON back with consistent fields. This makes it easy for you to consume.
The Prompt
I am sure you have already heard that the right prompt can make a huge difference to the quality of the response you get from Open AI. As of Jan 2024, this is the prompt I am using, but I am sure this will evolve.
You are an Oracle Technology blog analyzer assistant. Your goal is to determine if the blog post is related to Oracle Technologies. You will receive the content of a blog post and analyze it. Score the blog post on a scale of 0-5 indicating how relevant the post is to this comma separated list of topics: Oracle Application Express (APEX), Oracle REST Data Services (ORDS), Oracle Cloud Infrastructure (OCI), Oracle SQL (SQL), Oracle PL/SQL (PLSQL). Return a JSON object with each topic and its score. Use the value part of the topic name inside () as the topic JSON field name. A score of 0 should indicate not relevant at all an 5 indicates extremely relevant.
The Code
Armed with an Open AI API Key I can call Open AI using the PL/SQL code below.
This function generates JSON to send to Open AI:
p_modelis the Open AI Model the API should usep_system_msgis the prompt we want to send with our request.p_user_msgis the content of the blog post (I only pass the first 4,000 characters to limit the number of tokens I consume).
FUNCTION ai_payload_json
(p_model IN VARCHAR2,
p_system_msg IN VARCHAR2,
p_user_msg IN VARCHAR2) RETURN CLOB IS
l_payload_obj json_object_t := json_object_t();
l_format_obj json_object_t := json_object_t();
l_message_obj json_object_t := json_object_t();
lt_messages json_array_t := json_array_t ();
BEGIN
-- Build JSON Payload for Open AI Call.
l_format_obj.put('type', 'json_object');
l_payload_obj.put('model', p_model);
l_payload_obj.put('response_format', l_format_obj);
l_message_obj.put ('role', 'system');
l_message_obj.put ('content', p_system_msg);
lt_messages.append (l_message_obj);
l_message_obj.put ('role', 'user');
l_message_obj.put ('content', p_user_msg);
lt_messages.append (l_message_obj);
l_payload_obj.put('messages', lt_messages);
-- Convert Payload JSON to CLOB.
RETURN (l_payload_obj.to_clob());
END ai_payload_json;
This procedure takes the payload generated by the above function and calls Open AI:
PROCEDURE call_open_ai
(p_json_payload IN CLOB,
x_response OUT CLOB) IS
BEGIN
-- Set Header to tell Open AI to return JSON.
apex_web_service.set_request_headers
(p_name_01 => 'Content-Type',
p_value_01 => 'application/json',
p_reset => true);
-- Call the Open AI Completions API.
x_response := apex_web_service.make_rest_request
(p_url => 'https://api.openai.com/v1/chat/completions',
p_http_method => 'POST',
p_body => p_json_payload,
p_transfer_timeout => 30,
p_credential_static_id => 'OPEN_AI_TEST');
IF apex_web_service.g_status_code <> 200 THEN
raise_application_error (-20000, 'Call to Open AI API Failed');
END IF;
END call_open_ai;
If all goes well, I get a response like this:
{
"id": "chatcmpl-8j6p4677Yq4HYQGlDYJzozo1gZTVt",
"object": "chat.completion",
"created": 1705761678,
"model": "gpt-3.5-turbo-1106",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "{\n \"APEX\": 5,\n \"ORDS\": 0,\n \"OCI\": 0,\n \"SQL\": 4,\n \"PLSQL\": 5\n}"
},
"logprobs": null,
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 1102,
"completion_tokens": 40,
"total_tokens": 1142
},
"system_fingerprint": "fp_aaa20cc2ba"
}
The JSON we are looking for is embedded in the content field from the assistant response.
{
"APEX": 5,
"ORDS": 0,
"OCI": 0,
"SQL": 4,
"PLSQL": 5
}
This gives me a clean set of data that I can use to determine whether to exclude a particular blog post.
Searching Blog Posts
The website can search the content of all the blog posts that have been captured by the process above.
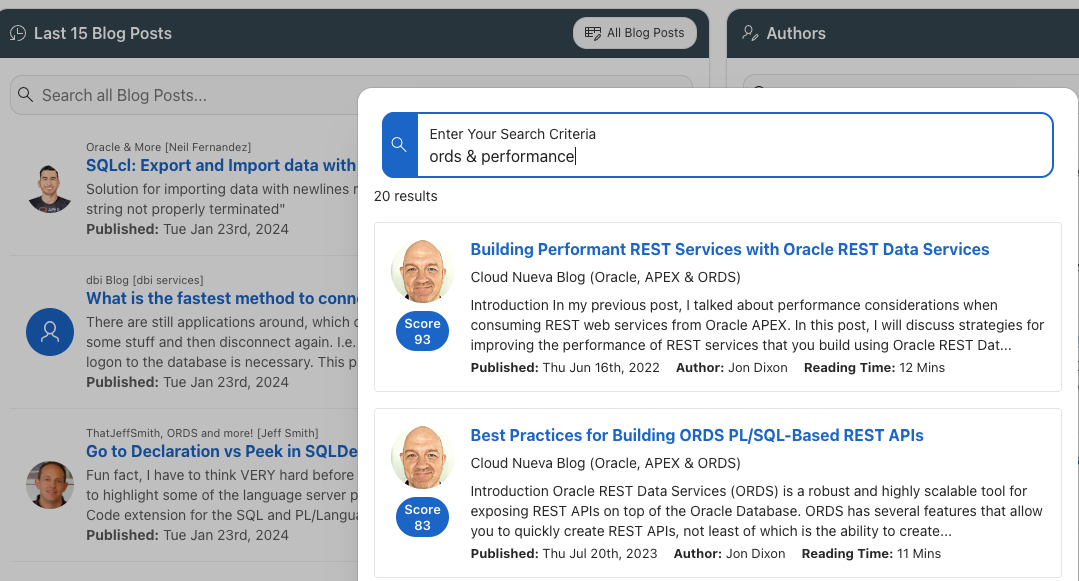
Oracle Text
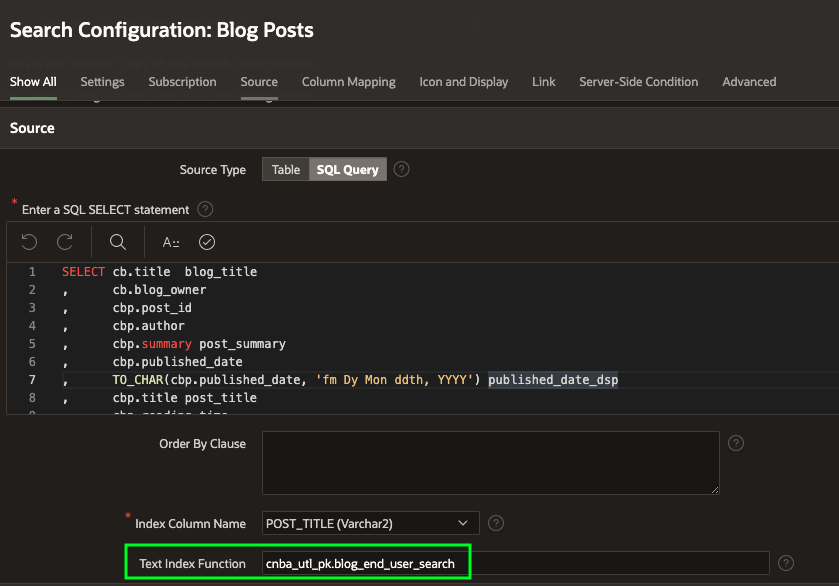
The engine behind the Search is Oracle Text. The UI for the search is embedded in an APEX Search Configuration. The search configuration references an Oracle Text Index Function:
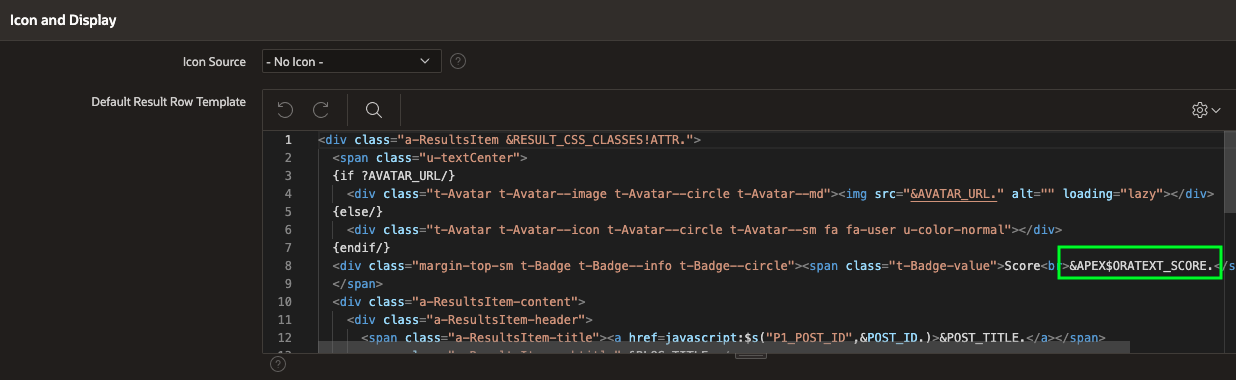
I have also customized the Result Row template to improve the UI and reference the score returned by Oracle Text.
The Oracle Text Index function looks like this:
FUNCTION blog_end_user_search
(p_search IN VARCHAR2) RETURN VARCHAR2 IS
c_xml constant varchar2(32767) := '<query><textquery><progression>' ||
'<seq> #SEARCH# </seq>' ||
'<seq> ?#SEARCH# </seq>' ||
'<seq> #SEARCH#% </seq>' ||
'<seq> %#SEARCH#% </seq>' ||
'</progression></textquery></query>';
l_search varchar2(32767) := p_search;
BEGIN
-- remove special characters; irrelevant for full text search
l_search := REGEXP_REPLACE( l_search, '[<>{}/*!$?:;\+]', '' );
-- Escape _
l_search := REPLACE( l_search, '_', '\_' );
RETURN REPLACE( c_xml, '#SEARCH#', l_search );
END blog_end_user_search;
The Oracle Text Index uses the following procedure to allow users to search over the title and the blog content:
PROCEDURE blog_index
(p_rowid IN ROWID,
x_xml IN OUT NOCOPY CLOB) IS
CURSOR cr_blog_post IS
SELECT title
, plain_content
FROM cnba_blog_posts
WHERE rowid = p_rowid;
lr_blog_post cr_blog_post%ROWTYPE;
BEGIN
OPEN cr_blog_post;
FETCH cr_blog_post INTO lr_blog_post;
CLOSE cr_blog_post;
x_xml := x_xml || TO_CLOB('<BLOG_POST>');
x_xml := x_xml || TO_CLOB('<TITLE>') || TO_CLOB(lr_blog_post.title) || TO_CLOB('</TITLE>');
x_xml := x_xml || TO_CLOB('<CONTENT>') || TO_CLOB(lr_blog_post.plain_content) || TO_CLOB('</CONTENT>');
x_xml := x_xml || TO_CLOB('</BLOG_POST>');
END blog_index;
Email Subscription
Another key feature of the website is the ability for users to subscribe to a weekly digest email. This email lists all the APEX Developer-related posts from the past week.
The process works as follows:
Sign-Up
Users provide their email and receive an email with a URL and token.
The token allows the user to access a page where they can verify their subscription.
Users can re-enter their email and get a new token anytime, allowing them to unsubscribe.
Weekly email
An APEX Automation runs every week to send an email to all subscribers.
The
apex_mail.sendPL/SQL API is used to send the email. In my case,apex_mailuses the OCI Email Delivery Service to send the email.I use APEX Email Templates to format the email.
Feeds
As well as offering a UI to search APEX Developer blogs, I also offer two feeds:
REST Feed Powered by Oracle REST Data Services (ORDS)
Because ORDS is easy to use, this feed was created with a single SELECT statement and exposed as a REST API. It even comes with comprehensive filtering capabilities using ORDS filtering Syntax.
Atom Feed
ORDS also powers the Atom feed, but the content is generated using the following code.
PROCEDURE atom_feed (p_page_num IN NUMBER) IS
l_response CLOB;
l_entries CLOB;
l_offset NUMBER;
l_latest_post_utc VARCHAR2(100) := get_latest_post_date;
BEGIN
-- Calculate Offset.
IF NVL(p_page_num,0) <= 0 THEN
l_offset := 0;
ELSE
l_offset := (p_page_num * GC_ATOM_PAGE_SIZE) - GC_ATOM_PAGE_SIZE;
END IF;
-- Build the Start of the XML for the Atom Feed using a Constant.
l_response := TO_CLOB(REPLACE(GC_ATOM_XML_START, '#UPDATED#', l_latest_post_utc));
-- Add the Blog Posts for the current page.
WITH posts AS
(SELECT cbpv.post_id
, cbpv.published_date
, cbpv.post_title title
, cbpv.summary
, cbpv.link
, cbpv.author
, TO_CHAR(SYS_EXTRACT_UTC(cbpv.published_date),'YYYY-MM-DD"T"HH24:MI:SS"Z"') updated
FROM cnba_blog_posts_v cbpv
ORDER BY cbpv.published_date DESC, post_id
OFFSET l_offset ROWS
FETCH FIRST GC_ATOM_PAGE_SIZE ROWS ONLY)
SELECT xmlagg
(xmlelement ("entry",
xmlelement("title", title),
xmlelement("link",xmlattributes(link AS "href")),
xmlelement("updated", published_date),
xmlelement("author",xmlelement("name", author)),
xmlelement("summary", summary),
xmlelement("id", link)
)).getclobval() INTO l_entries
FROM posts
ORDER BY published_date DESC, post_id;
-- Complete the Response.
l_response := l_response || l_entries || TO_CLOB('</feed>');
-- Set Mime Header and return response.
owa_util.mime_header('application/atom+xml');
apex_util.prn (
p_clob => l_response,
p_escape => false );
END atom_feed;
From a User Perspective
I want to finish this post by showing you an end-user view of the main features of the APEX Developer Blogs Website.
Home Page
The home page shows you the last 15 blog posts and a list of the Blogs on the platform.
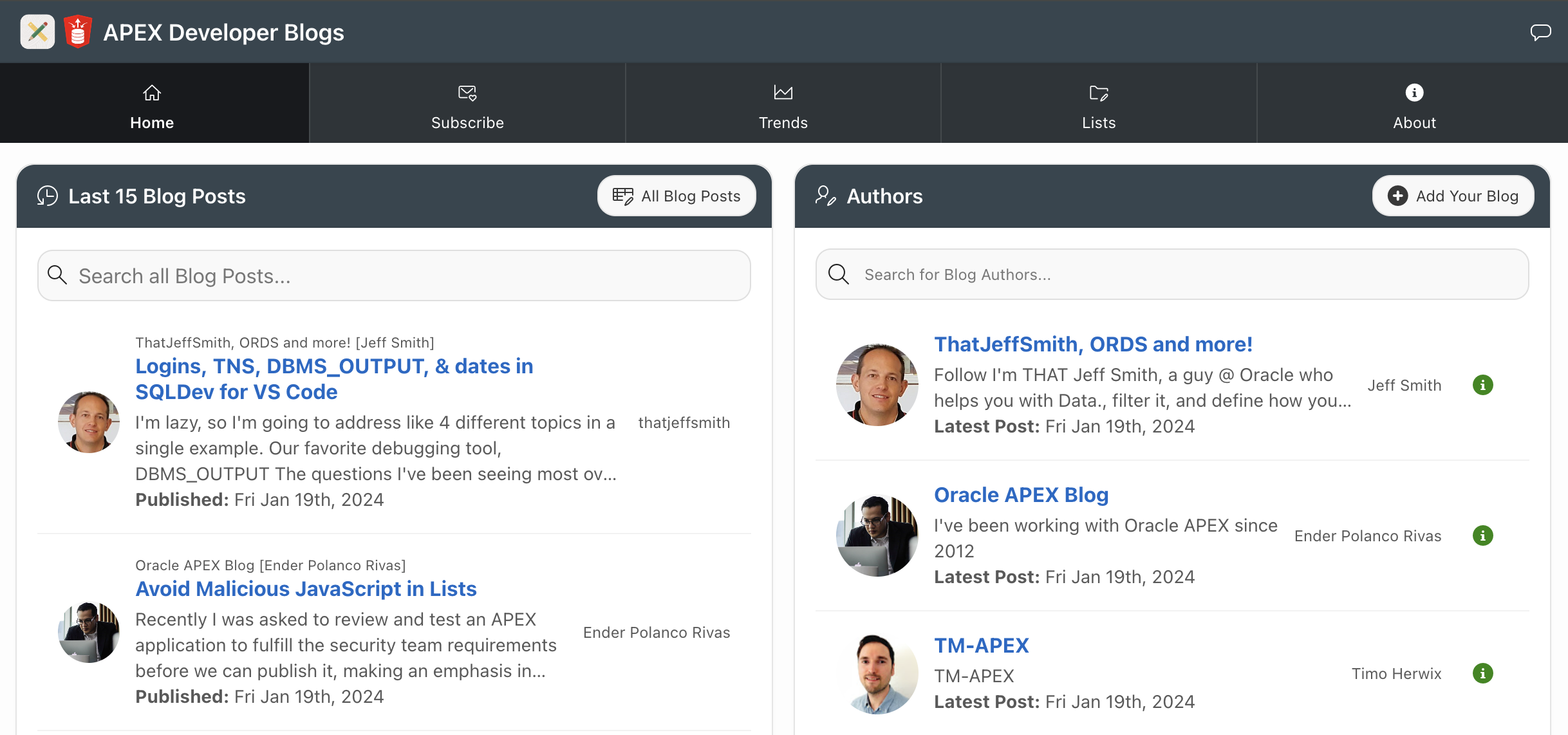
You can search for content across all of the captured blog posts using an Oracle Text Search.
Blog Search
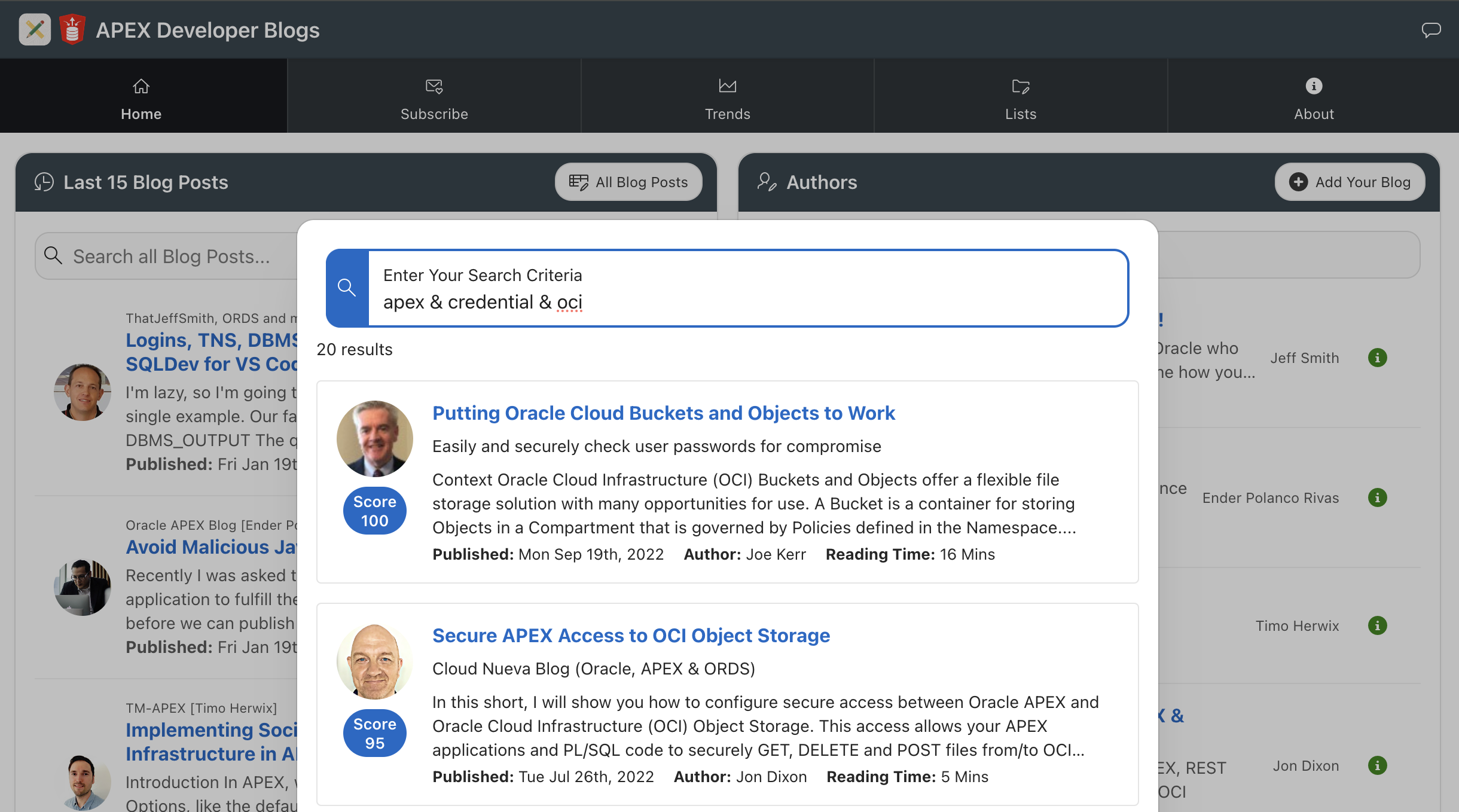
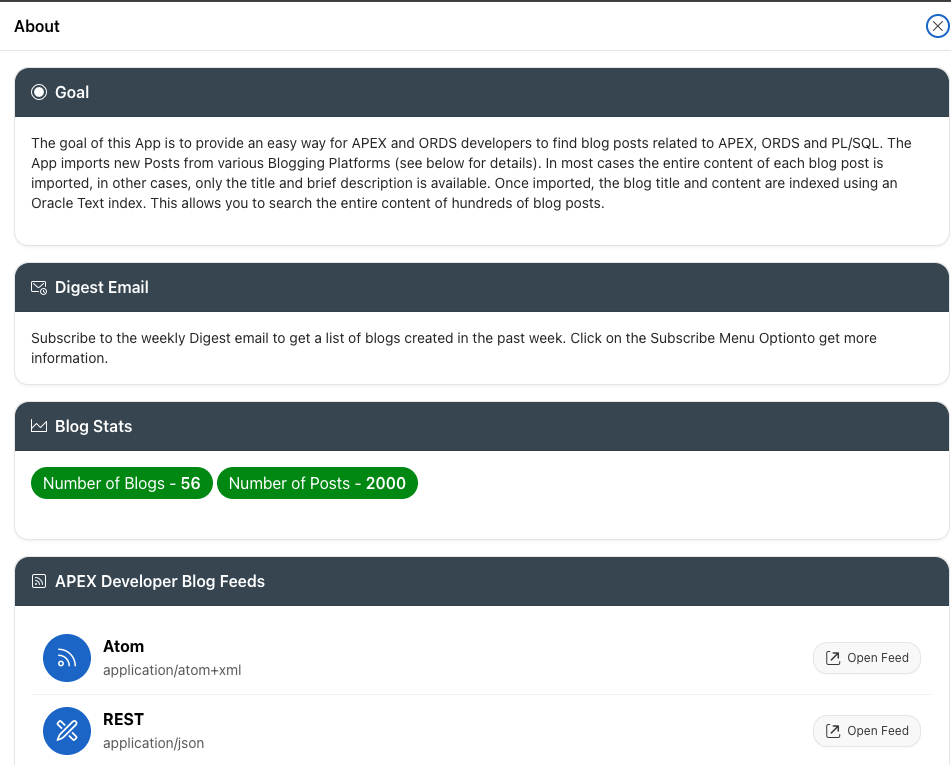
The About Page provides some background information and links to an Atom Feed and a REST API where you can access all of the blog posts captured by this site.
About Page
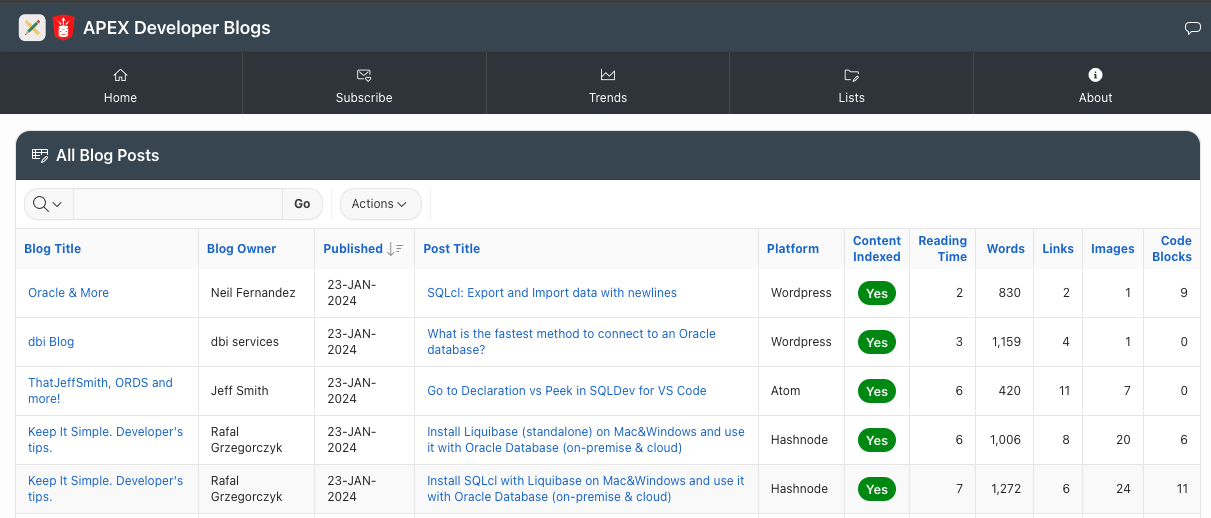
All Blog Posts Report
The All Blog Posts Report (accessible from the home page) provides an APEX Interactive Report showing all the blog posts captured by the website.
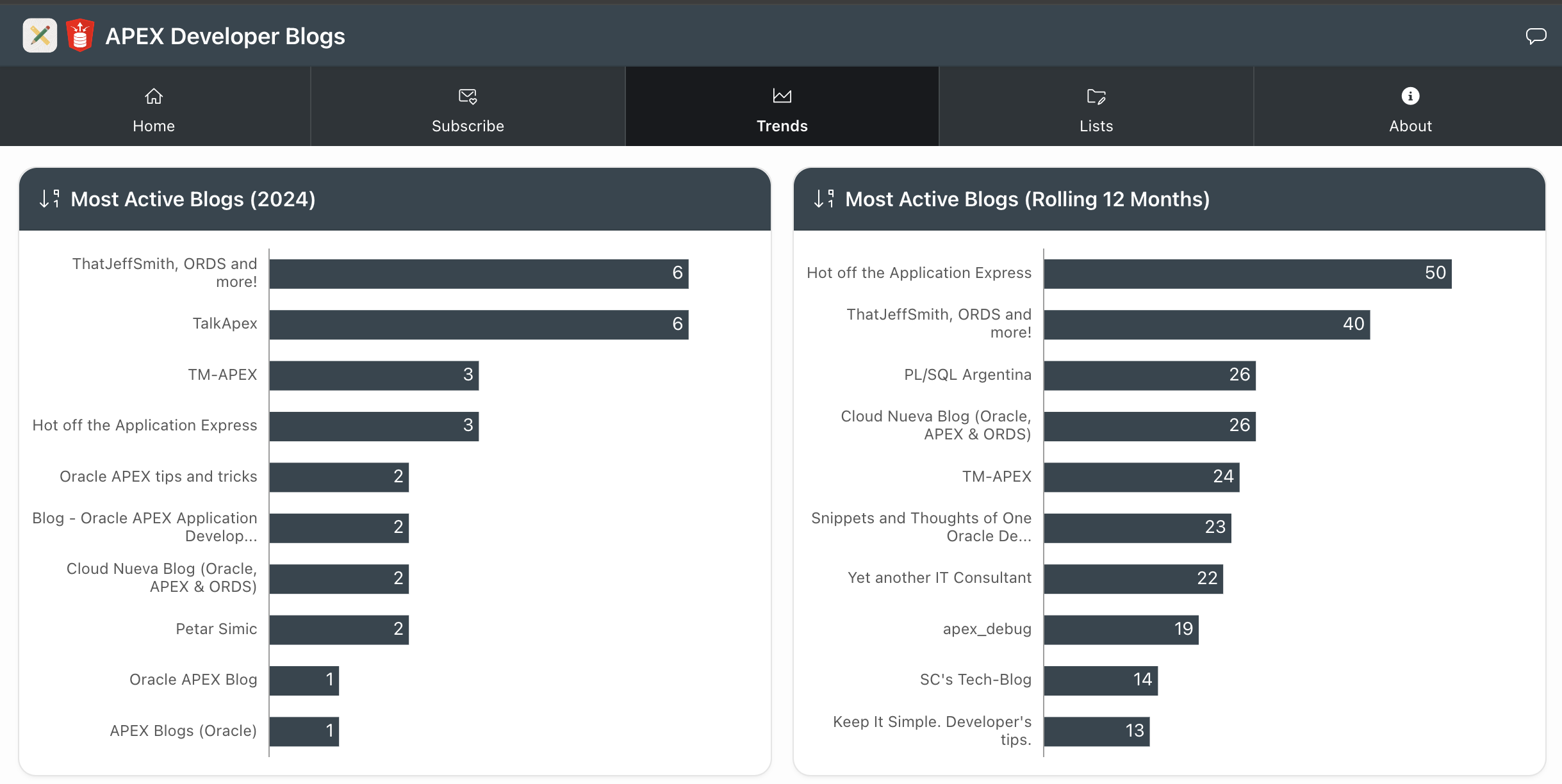
Trends
The Trends page shows stats like the most active bloggers and how many posts.
Email Subscription
Finally, the subscribe page allows you to sign up for a weekly digest email with all the APEX Developer-related blogs discovered during the week.
Website Stats
This section highlights some of the stats related to the APEX Developer Blogs Website. These stats were captured on Jan 23rd, 2024.
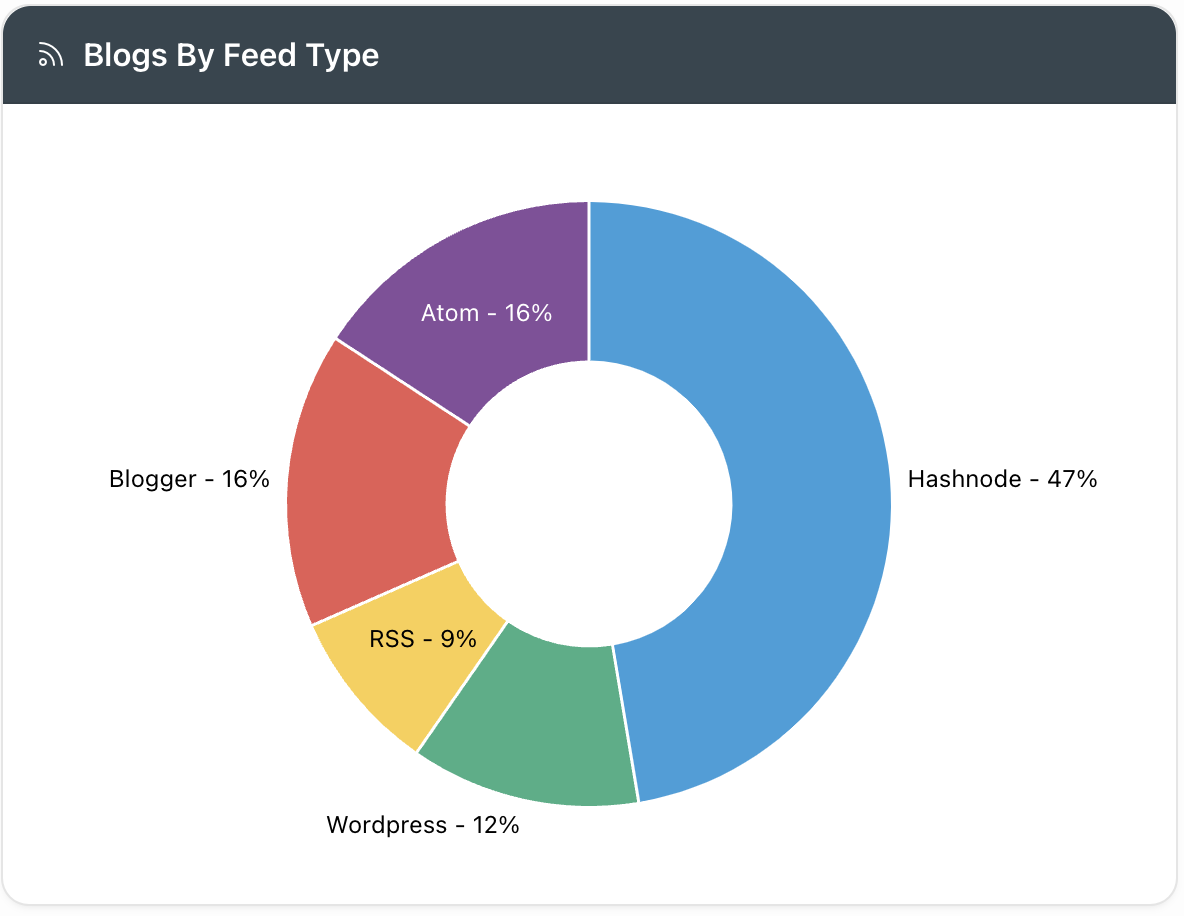
Most Popular Blog Platform for APEX Developers
Hashnode is by far the most popular platform for APEX Developers.
Blogs and Posts
Page Views
Email Subscribers
Platform
The Oracle Developer Blogs website is hosted on the OCI APEX Application Development Service. This is the same platform where I run my internal applications and demos.
Conclusion
I had a lot of fun building the APEX Developer Blogs Website and learned a lot while doing so. These kinds of side projects allow me to try out APEX Features (and other technologies) that I would not often need to use in my day-to-day job. Hopefully, the APEX community also finds the site useful.