Turn Complex Logic into Simple SQL using Pipelined Table Functions
Introduction
Occasionally you need to use every tool in the ToolBox 🧰. Pipelined Table Functions are one of those tools you won't need to use often, but when you do, you are glad they exist. This post will explain what a pipelined table function is and describe some use cases where they can be useful.
⚠️ Before I go any further, please adhere to the golden rule; "If you can do it in SQL, then you should do it in SQL"
What I mean by this is that you should only use pipelined table functions once you have exhausted your options with SQL.
What is a Pipelined Table Function
A pipelined table function is a PL/SQL function that allows you to select rows and columns like a table or view. The difference is that you get to decide what is emitted in these rows and columns using PL/SQL code. This allows you to include complex logic in the function that you may not otherwise be able to handle in a SELECT statement.
Example
The code below represents a basic example of a pipelined table function. It is intended to show the mechanics of a pipelined table function as opposed to it being a good use case. However, it illustrates that you can perform any PL/SQL you like to generate the rows emitted from the pipelined table function.
See Martin D'Souza's post for more details on why I am trapping the NO_DATA_NEEDED exception.
I could have created a PL/SQL Object TYPE instead of defining the
rec_evs_soldtype in the Package Specification. I prefer to include object types in the package spec as it makes deployment easier and keeps the type with its related code. My understanding is that behind the scenes, Oracle will create a PL/SQL Object Type for record types specified in the package specification anyway.
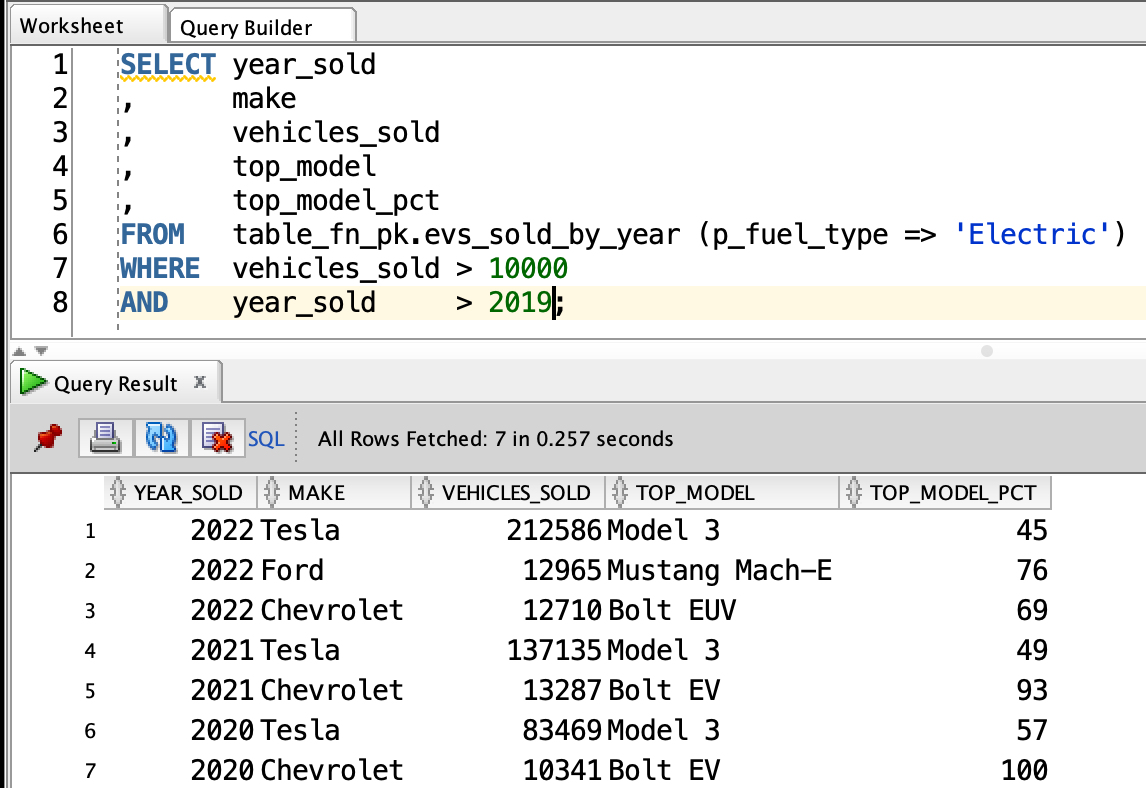
The screenshot below shows an example query and result. FYI, the data set I am using represents EV sales in California.
Note: If you are using an older version of the Oracle Database (i.e., prior to 12.2), then you need to include the TABLE operator. e.g.
SELECT *
FROM TABLE(table_fn_pk.evs_sol_by_year (p_fule_type => 'Electric'));
Use Cases
Now that we are level set on what a pipelined table function is and how it works, let's look at some situations where they are helpful.
When I need to perform many complex calculations on data and return the results as a SQL query. Sometimes you need to run lots of SQL statements and call numerous functions and procedures to transform and enrich data to be presented in a dashboard or summary view. Accessing this transformed data via a simplified SQL statement is especially useful for APEX dashboards, charts, card regions, etc.
When the calculations I need to perform are conditional. In some situations, I need to perform all of the calculations in the pipelined table function, but in others, I only need to perform a subset of them. In cases like this, you can sometimes improve performance Vs. a single SQL statement, as you only call the expensive code when needed.
Pipelined table functions are helpful when the data source can be completely different based on the input parameters. For example, I may want to show users locally cached data but allow them to query live data from a REST end-point under certain circumstances. In a pipelined table function, I can include logic to determine whether to use the cached data or call the REST APIs to get the latest data.
To handle REST Service pagination. Sometimes when you call a REST API, you must traverse multiple pages of data to get the entire result set. With a pipelined table function, I can present a simple SELECT statement to APEX and, within the pipelined table function, call a REST API and iterate through the pages of data emitting them to the APEX report. The APEX report can then handle pagination for me as it would for any other SQL statement.
- Note: You could create an APEX REST Source Plugin to handle pagination and then base the report on a REST Source. That is a topic for another blog post 😊
APEX_APPROVALS.GET_TASKS
I was prompted to write this post when I noticed that the APEX Approvals functionality utilizes a pipelined table function to get a list of approvals (APEX_APPROVALS.GET_TASKS). I assume the APEX team chose this approach because complex logic is required to fetch and present the tasks. I also suspect even though the logic changes significantly based on the p_context parameter, they wanted to provide a consistent and easy-to-use interface for APEX developers. This approach also allows them to change the logic within the function in future releases without changing the interface.
What About APEX?
As you may have noticed, I have not gone into much detail on how to utilize pipelined table functions in your APEX Apps. To be honest, there is not much detail to go into. As far as APEX is concerned, a pipelined table function is just another SQL statement.
The ability to obfuscate complex logic behind simple SELECT statements makes incorporating this logic into your APEX applications easier. It also allows you to change the underlying logic without necessarily changing your APEX apps. Usually, we can do this with views, but sometimes only pipelined table functions can give us the results we need.
Conclusion
Pipelined table functions are an invaluable tool when you have run out of options with SQL. I encourage you to add them to your development toolbox 🧰.