Move Large Volumes of Data Over REST with APEX & ORDS

Introduction
On a recent project, I was faced with the need to Sync large volumes of data from one instance to another over REST. This post will review several options for achieving this using APEX and ORDS.
For the sake of this post, I will consider a sample table with 100,000 rows and ten columns. These rows and columns equated to twenty-three MB of data when exported to a JSON document.
The goal is to move the content of this table between two Oracle Databases over REST as efficiently as possible. I will call these instances the Source Instance (where the data is created) and the Target Instance (where we want to get the data to).
REST Data Source Synchronization
The most obvious approach is to create a simple ORDS REST Service in the Source Instance. Then, create an APEX REST Data Source in the target instance and enable REST Data Source Synchronization.
Source ORDS Handler
In the source instance, I have created a simple ORDS GET Handler that selects all of the records and columns from the table rest_transfer_test. Note: The ORDER BY is essential here so that ORDS can accurately paginate the response.
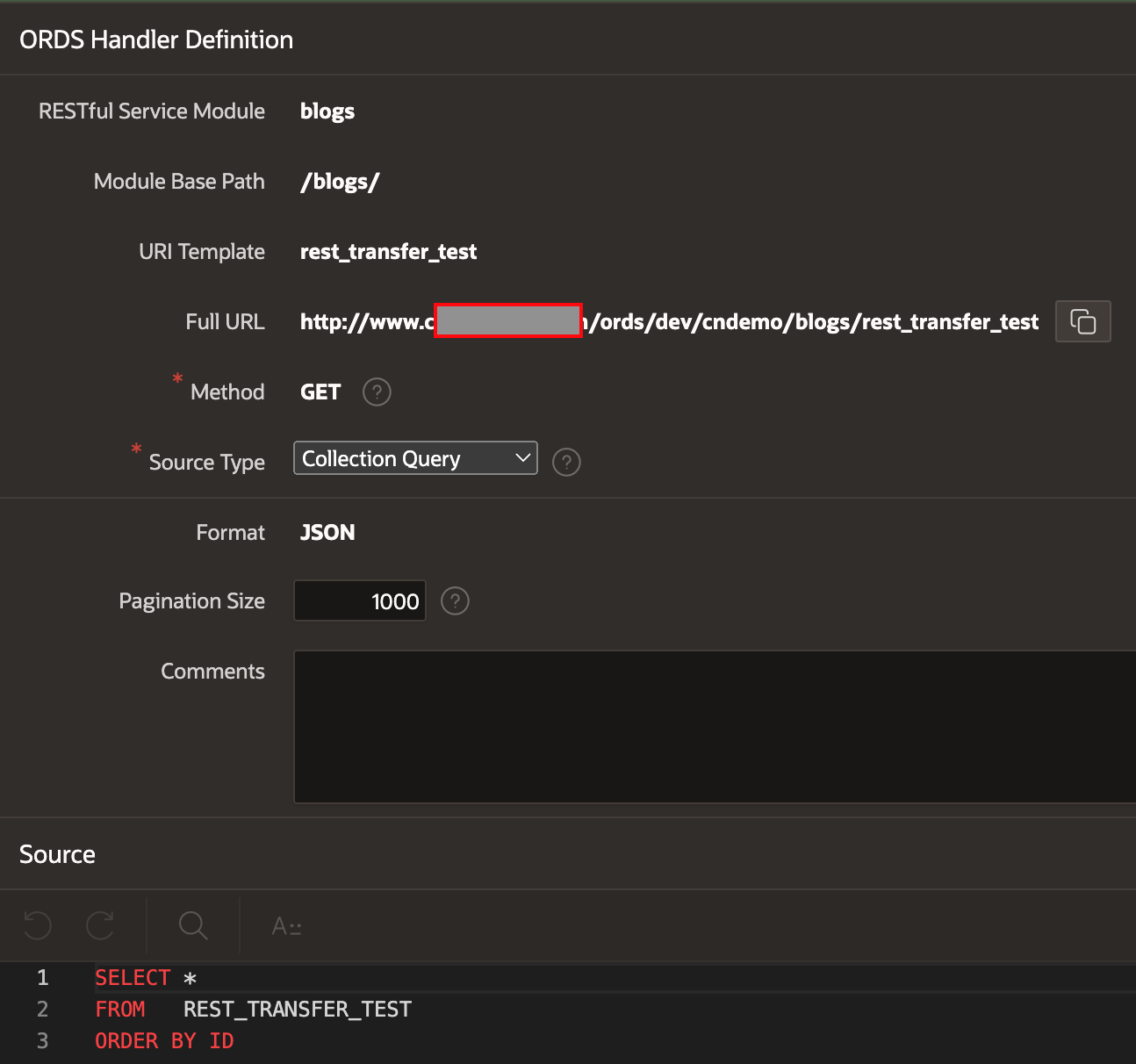
In the screenshot above, I have set the pagination size to 1000. I will come back to this later in the blog.
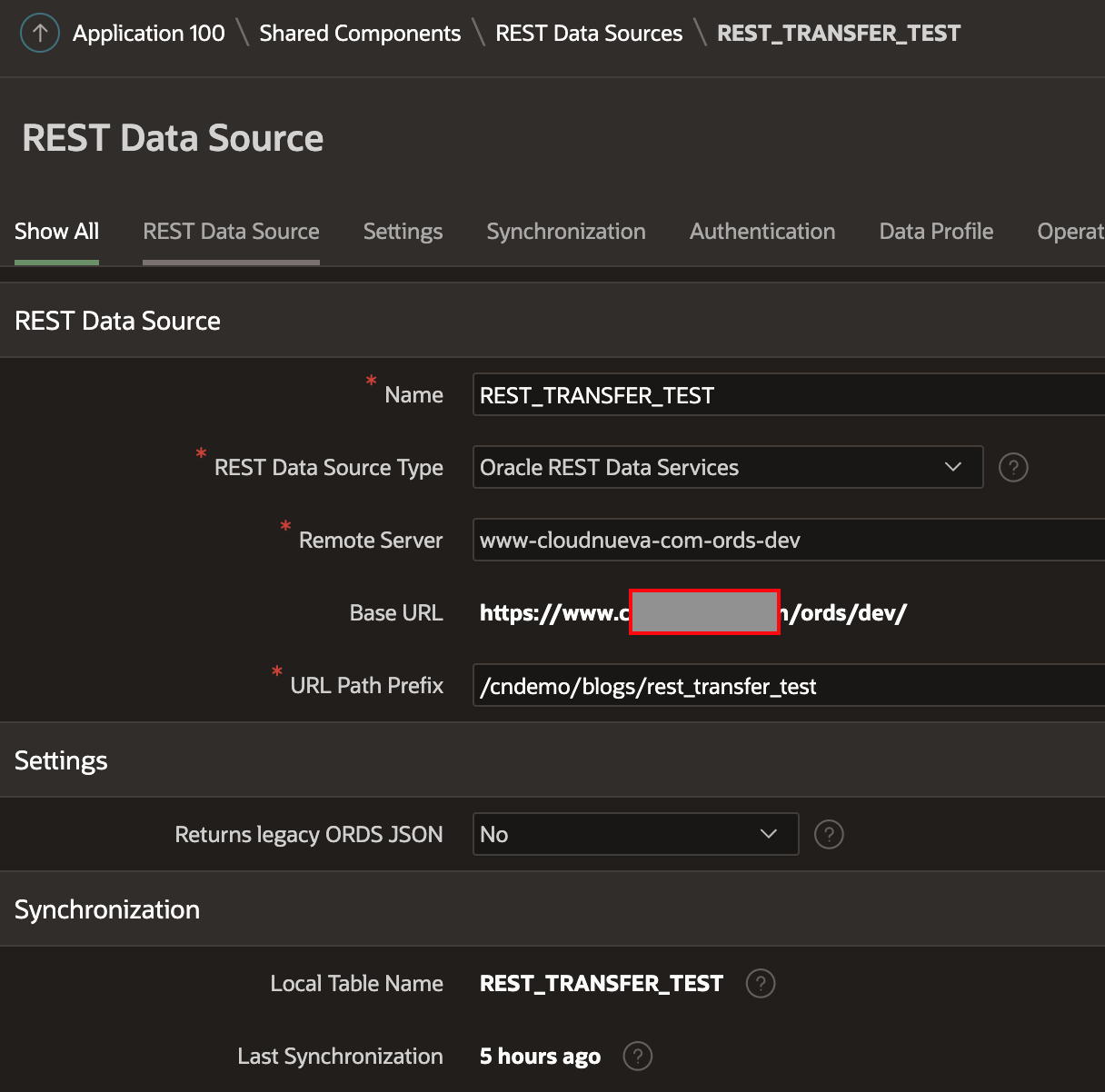
Target APEX REST Data Source
Next, I created a REST Data Source in the Target Instance. The REST Data Source points to the REST Service we created in the previous step.
 Finally, I enabled Synchronization for the REST Data Source
Finally, I enabled Synchronization for the REST Data Source
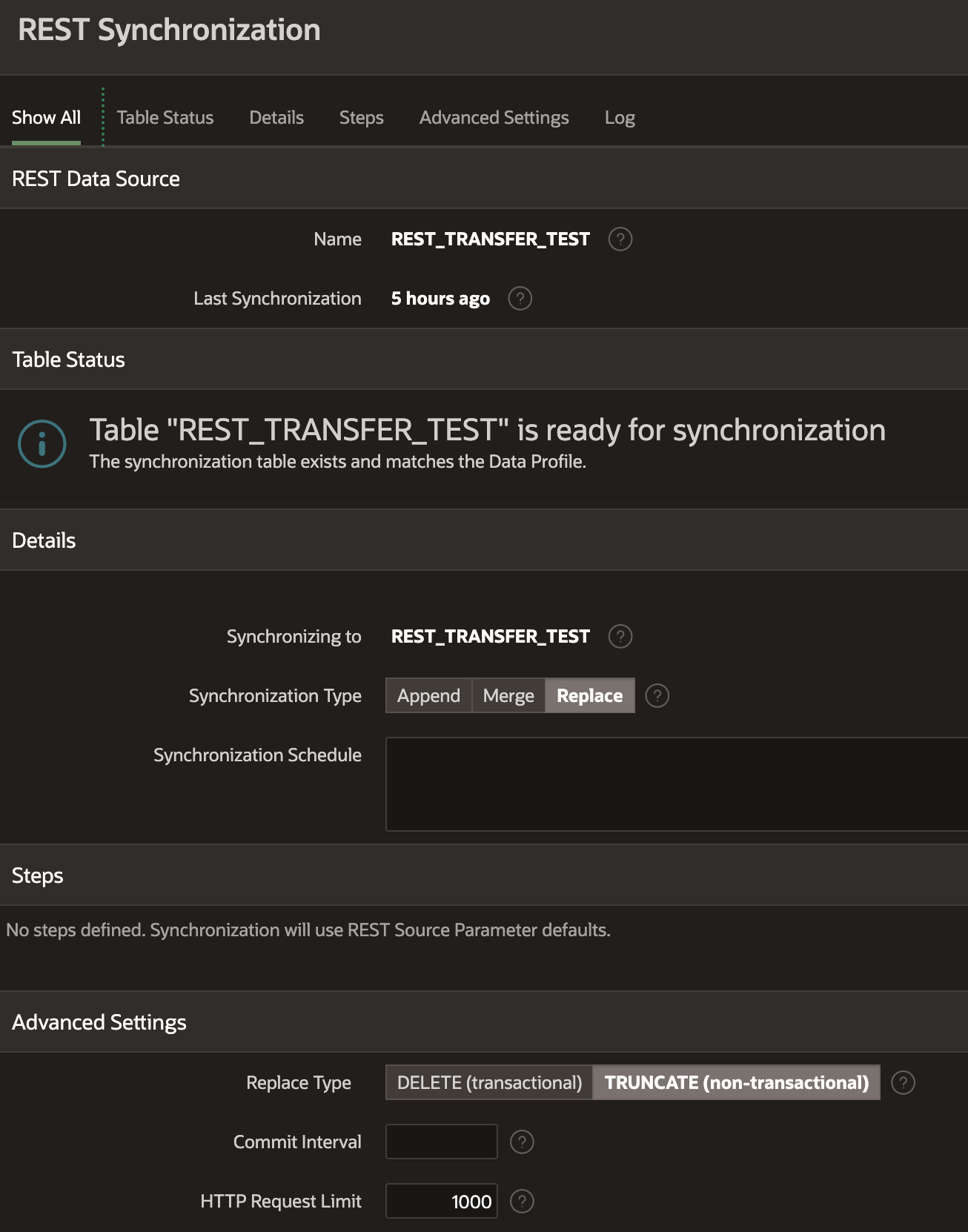
Note: The 'Synchronization Type' is 'Replace', and the 'Replace Type' is 'TRUNCATE'. This means that APEX will truncate the table in the Target before running the Sync.
Findings
- I ran the Sync from the REST Data Source in the Target Instance three times
- Each time, I adjusted the page size of the ORDS Handler in the Source Instance
- This experiment illustrates how the timings are impacted by page size
Here is a screenshot of the REST Sync Log for the three Sync process runs.
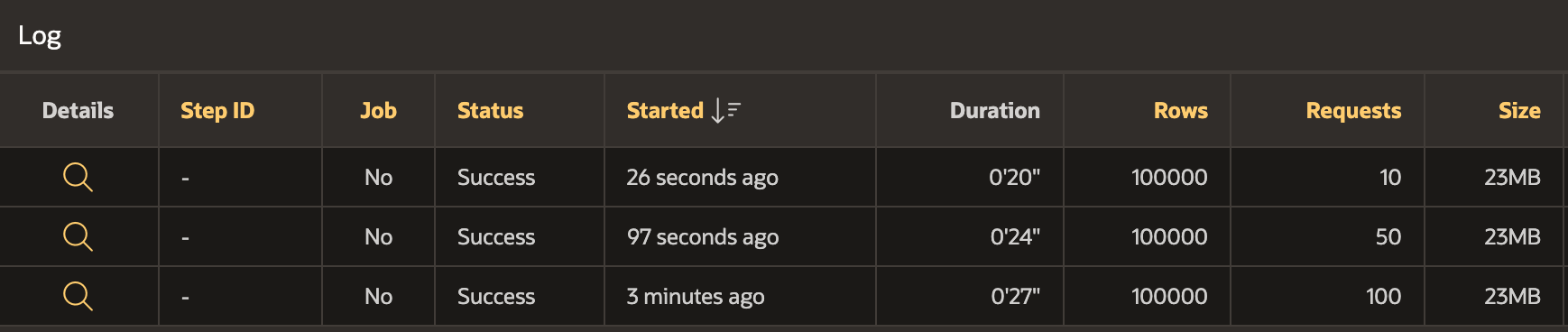
Run 1 - Pagination of Source ORDS Handler set to 1,000
- It took 100 requests for the Sync to fetch all 100,000 rows
- It took ⏳27 seconds to Sync all 100,000 rows
- Run 2 - Pagination of Source ORDS Handler set to 2,000
- It took 50 requests for the Sync to fetch all 100,000 rows
- It took ⏳24 seconds to Sync all 100,000 rows
Run 3 - Pagination of Source ORDS Handler set to 10,000
- It took ten requests for the Sync to fetch all 100,000 rows
- It took ⏳20 seconds to Sync all 100,000 rows
- ❗10,000 is the largest value we can set the pagination size to for an ORDS REST Source
We are looking at about 20 seconds to Sync 100,000 records with almost no code. Not Bad!
- We can conclude that the larger the page size, the faster the Sync
- I suspect that even if we could set the pagination size > 10,000, we would experience diminishing returns and risk putting an undue load on the ORDS server
- You should fine-tune the page size for the Source ORDS Handler to get the fastest timings for your case
- In all three tests, the Sync fetched a total of 23 MB of data (which makes sense)
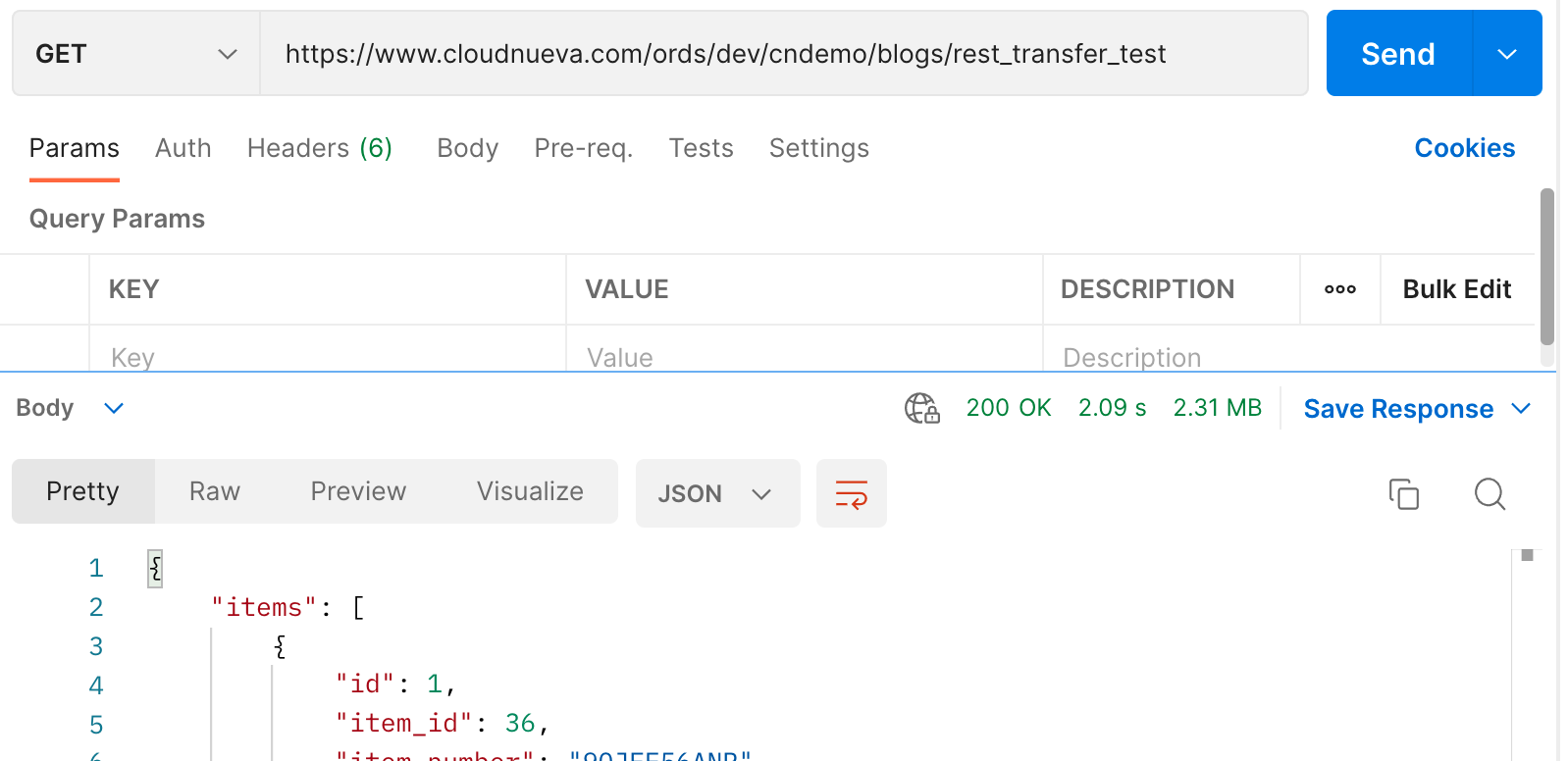
- Interestingly, if we use Postman to call the Source Instance REST Service, we can see that when the page size is set to 10,000, it takes just over 2 seconds to fetch 2.3 MB of data. This tells us that nearly all of the time is taken calling the REST service and transporting the data across the network, and hardly spent any time processing the response
All PL/SQL
This approach will build a PL/SQL block in the Target instance. The PL/SQL block calls the Source ORDS Handler, fetches batches of 10,000 records, and inserts them into the table.
At the end of an ORDS GET Handler response, ORDS provides metadata about the payload (see below for example). The code uses this to determine if it has rows to process and if there are more rows to fetch.
"hasMore": true,
"limit": 10000,
"offset": 0,
"count": 10000,
"links": [
{
"rel": "self",
"href": "http://www.example.com/ords/dev/cndemo/blogs/rest_transfer_test"
},
{
"rel": "describedby",
"href": "http://www.example.com/ords/dev/cndemo/metadata-catalog/blogs/item"
},
{
"rel": "first",
"href": "http://www.example.com/ords/dev/cndemo/blogs/rest_transfer_test"
},
{
"rel": "next",
"href": "http://www.example.com/ords/dev/cndemo/blogs/rest_transfer_test?offset=10000"
}
]
Findings
- It took 56 lines of code to build the solution
- The average duration over three runs was ⏳ 23 seconds, so not as good as the declarative approach. Score 1 for the APEX development team 😊
- This is somewhere between REST Data Source Sync and CSV Bulk Load
- This approach does give us a lot of flexibility to perform other logic before inserting records into the Target table.
- Having to parse the payload twice, once to get the count of rows and next URL and once to get the data, would have slowed this down considerably
CSV Batch Load Via REST Enabled Table
So far, the best we have done is twenty seconds. This is OK, but I think we can do better. When you REST enable a table using ORDS, you also get access to an endpoint called /batchload. Doing this allows you to send a csv CLOB and have ORDS parse the csv and load the table. You can specify how many rows are sent in each batch, when ORDS should commit, and if ORDS should truncate the table before performing the load.
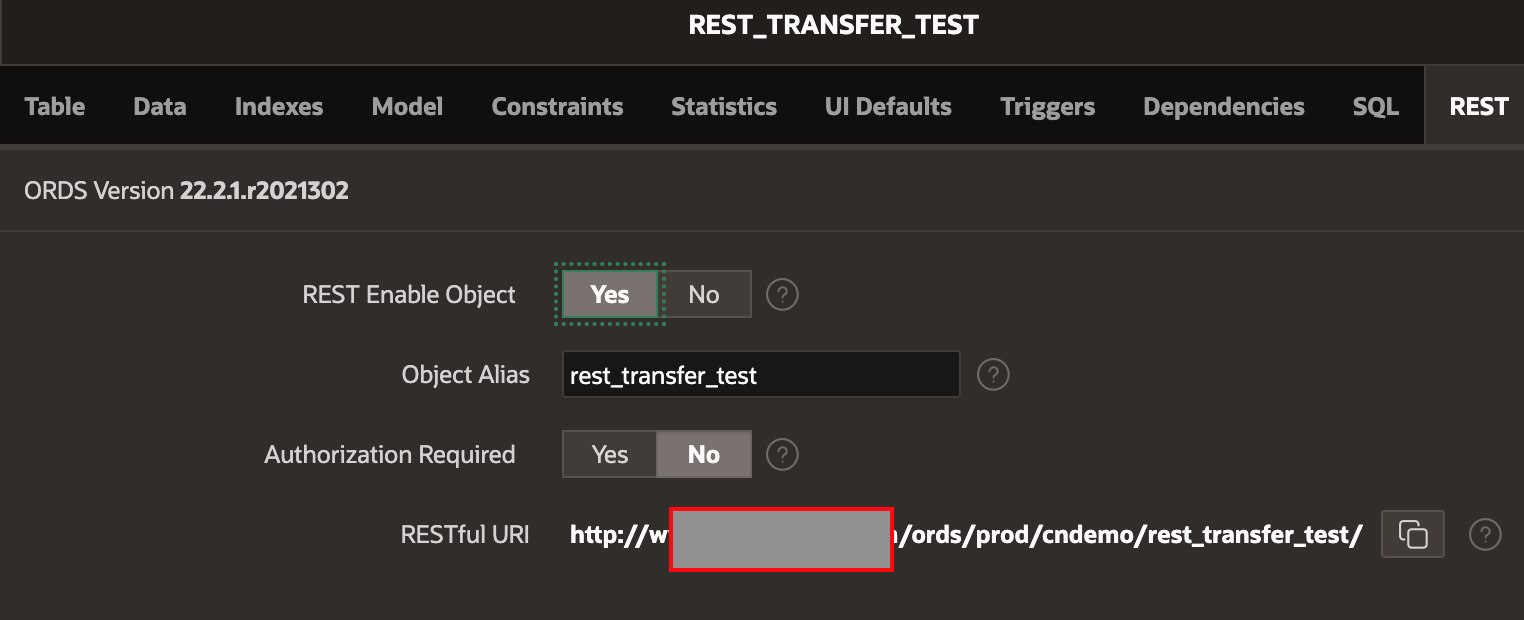
REST Enable the Table
Start by rest enabling the table in the target instance. In the screenshot below, I have done this from APEX Builder.
Build CSV and POST to Table
The code below is run from the Source instance. It builds a csv CLOB from the source table and then calls the table's ORDS handler in the Target instance.
The response from the /batchload service (if successful) looks like this:
Response: #INFO Number of rows processed: 100,000
#INFO Number of rows in error: 0
#INFO Last row processed in final committed batch: 100,000
SUCCESS: Processed without errors
Findings
- The average duration over three runs was ⏳ 14.9 seconds, which is 25% faster than REST Sync or All PL/SQL
- Building the
csvCLOB to send to the Target instance takes about 2 seconds out of the 14.9 seconds total
- Building the
- This performance improvement is likely because the
csvcontent is 9 MB instead of 23 MB for the JSON, which improves network transfer time. We are also able to POST all 100,000 records at once - It took 43 lines of code to build this solution
- As Jeff points out in his blog post, the
batchloadapproach performs individual INSERT statements, which is not the most efficient approach for bulk loading data
ORDS PL/SQL and APEX_ZIP
We are improving the timings, but I think we can do even better. What if we could generate all of the JSON on the source, ZIP it, and then bring it over? That should eliminate a lot of the network traffic overhead.
Source ORDS Handler
I created a new ORDS handler on the Source instance as follows:
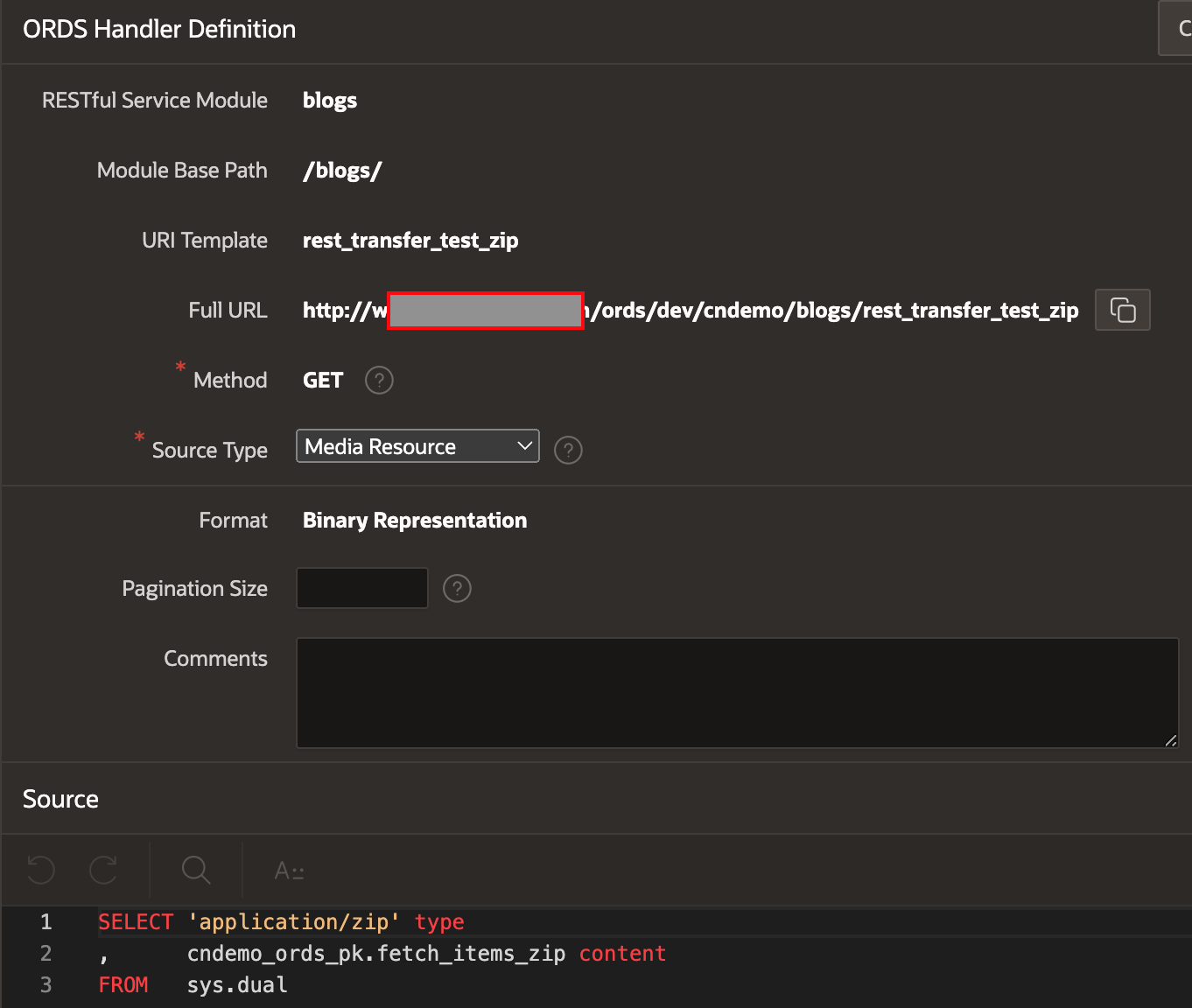
The below Gist contains the code called by the function fetch_items_zip in the ORDS Handler:
Target PL/SQL Code
In the target instance, we can run code similar to the below. This code calls the Source ORDS Handler, unzips the response, converts the JSON BLOB to a CLOB, and parses and inserts the JSON into the table.
Findings
- The average duration over three runs was ⏳ 4.1 seconds 🎉
- If we call the REST Source from Postman, we can see that fetching the zip takes about 2.4 seconds of the 4.1 seconds
- We can also observe that we only had to fetch 2.3 MB of data instead of 23 MB.
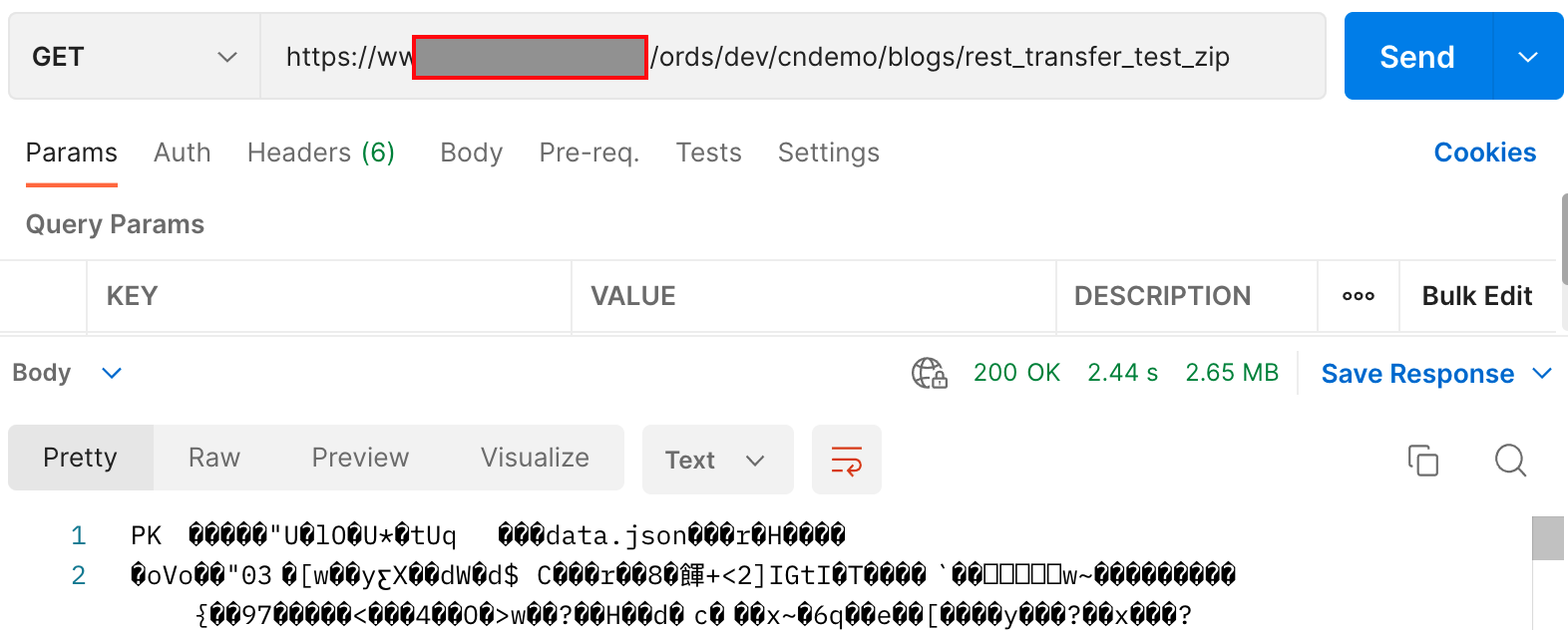
- Reducing the payload size and the number of requests improved performance significantly
- There is a limit, however, on how far this will scale, as the larger the ZIP, the more memory you will consume
- On the Source, generating the JSON CLOB and ZIP will consume memory
- Unzipping the BLOB and parsing the resulting JSON on the target will consume memory
- From experience, however, I can say that you can get into the 4-5 million records range and still expect to see response times of less than five minutes (depending on your hardware, of course)
- On the downside, we had to write 37 lines of code to accomplish this; which is still not bad considering the performance gained
REST Enabled SQL
What about REST Enabled SQL? Could that help us? I tried using APEX_EXEC and REST Enabled SQL to call a function on the Target instance cndemo_ords_pk.fetch_items, which generates the JSON and then returns a CLOB of the JSON.
However, as soon as I got over 100 records, I started getting the error ORA-20999: Error on Remote Server: ORA-06502: PL/SQL: numeric or value error. I got this error even though my bind variable was defined as a CLOB, so I think this may be a 🪲
It would have been even better if I could have returned a zipped BLOB of the JSON, but unfortunately, there is no apex_exec.get_parameter_blob function.
Conclusion
As you can see, with technology, there are invariably many ways to achieve the same result. It does, however, pay to do a few proofs of concept to review the options and see which one will work out best for your use case. 💡 Please leave a comment if you can think of any other creative ways to move large volumes of data between two databases over REST.
Also, read more about how to build performant REST Services and how to consume REST services more efficiently by reading the posts mentioned below.