Improving Performance when Consuming REST Services with Oracle APEX

Introduction
APEX provides two features, REST Data Sources and REST Enabled SQL which allow you to access data from other systems via REST. Not only that, but these features will enable you to use the results declaratively in many APEX components, such as Interactive Reports, Interactive Grids, Charts, List of Values, etc.
The ability to get real-time data from other systems is fantastic. In most cases, this removes the need for costly integrations.
Having said that, if you overuse REST calls in your APEX pages and you do not consider performance, this will introduce performance issues. Even the fastest REST service call is going to take .25 of a second or so if you factor in the following:
- The time it takes to call the REST service (network)
- The time it takes to execute the API behind the REST service
- The time it takes to receive the response (network)
- The time it takes to parse and process the response
In this post, I will discuss strategies for improving performance when calling REST services from APEX. These strategies include REST Source Synchronization and caching. I will describe each strategy with the following use case.
Use Case
In 2021, I moved to San Diego and wanted to know when the Tide Levels were low enough to walk on the beach. This was around the time PWAs were introduced in APEX 21.2. So, I thought I would build an APEX App to get the current and forecast tide levels. I found that the National Oceanic and Atmospheric Administration (NOAA) had several REST services, which would get me the data I needed.
Specifically, the following REST Services:
- Locations (list of monitoring stations)
- Tide Predictions (forecast tide levels for a given location)
- Water Level (the current tide level at a given location)
I have included a screenshot (below) from the App I built. This will help me visualize how I use the three NOAA REST services.
 The screenshot highlights the following information:
The screenshot highlights the following information:
- A map of the selected location (from the Locations REST Service)
- The 'Latest Tide Level' (from the Water Level REST Service)
- 'Today's Sunrise / Sunset' (from https://api.sunrise-sunset.org - not discussed in the blog post)
- The '7 Day Forecast' (from the Tide Predictions REST Service)
You can try the App out yourself here
📥 You can download the App here. The App was created in APEX 22.1.
Creating REST Data Sources
I started by creating a REST Data Source for each NOAA web service. I won't be covering how to create REST Sources in this post, but I will discuss a number of the settings later.
 Creating the REST Sources was made easier because none of the APIs require credentials. Having said that, APEX Web Credentials make creating and managing Web Service credentials easy.
Creating the REST Sources was made easier because none of the APIs require credentials. Having said that, APEX Web Credentials make creating and managing Web Service credentials easy.
It is worth pausing here to discuss Web Credentials and OAuth2 Token Caching. If you use REST Sources in native APEX components or call APEX_WEB_SERVICE.MAKE_REST_REQUEST, then APEX will cache OAuth2 tokens. When you call a secured web service, APEX will first call the Token URL associated with the Web Credential and cache the token and expiration. APEX will only call the OAuth server to get a new token when its current token has expired. This saves a whole round trip to the authentication server for every web service call you make to a secured end-point.
Once I had the REST Data Sources in place, I could incorporate them directly into my application. Before I did that, I needed to stop and consider performance.
Considering Performance at Design Time
Performance should be considered during application design (just like security and the requirements). For this reason, I needed to consider how I would use each of the three NOAA web services.
Locations
I quickly realized that the Locations (monitoring stations) web service would get used the most. Users need to select a location before they can do anything, and I want to show the location information on every page view. The list of locations is relatively static and is updated daily at most. Conclusion: Store the locations locally and Sync them from the NOOA web service every night.
Tide Predictions
As the name indicates, the Tide Predictions service provides forecast data, so we don't need to fetch data from the source for every page view. Conclusion: Call the NOAA web service once per hour and cache the response locally for the remainder of the hour.
Water level
The Water Level API fetches the current tide level, so we need to see the latest value every time. The payload is small (just the tide level), and the web service is fast. Conclusion: Fetch the latest value from the NOAA web service without caching.
Implementing the Three REST Services
This post assumes you are familiar with REST Data Sources, and I won't cover their creation in detail here.
Locations using REST Synchronization
REST Synchronization allows you to configure your REST Source to periodically call its related REST Service and synchronize the result to a local database table. You can then use that table in your APEX application with zero latency. You must identify a primary key column in the REST Source 'Data Profile' (during the creation of the REST Source). I have identified the 'id' column as the primary key in the screenshot below. The primary key column should also be the primary key in the local sync table.
 Once you have created (and tested) the REST Source, you can click 'Manage Synchronization' on the right-hand side.
Once you have created (and tested) the REST Source, you can click 'Manage Synchronization' on the right-hand side.
 APEX then opens the setup page below and asks you if you want it to create a new local table to sync to or you can identify an existing table. After that, you can set up the remaining REST Synchronization options. I won’t go into a discussion of the setups, but I would like to cover a few of the essential options below.
APEX then opens the setup page below and asks you if you want it to create a new local table to sync to or you can identify an existing table. After that, you can set up the remaining REST Synchronization options. I won’t go into a discussion of the setups, but I would like to cover a few of the essential options below.

Table Status If you select an existing table to sync to, then APEX will compare the columns in that table to your REST Source Data Definition. If it finds any differences, then it will highlight them here. It will even provide a script to alter your table to match the REST Source Data Definition. If you elect to sync to an existing table, you will always see a discrepancy (even if the table columns match the REST Source Data Profile columns). This is because APEX adds a couple of extra columns to track synchronization. Note: You do not need these extra columns for REST Synchronization to work.
Any columns in the REST Source Data Profile that are not in the local table are ignored. You can even ignore specific columns by marking them as 'Hidden' in the Data Profile.
Synchronization Type This option determines what APEX will do with existing rows when the Synchronization runs:
- Append: Append rows to the local table. This is typically used when no primary key has been defined in the data profile.
- Merge: Merge rows into the local table. The data profile must have a Primary Key defined to use this option. If a row for the given primary key value exists, the row will be updated. Otherwise, the row will be created.
- Replace: Empty the local table before loading new data.
Synchronization Schedule You can define a schedule using the same DBMS_SCHEDULER calendaring syntax used by APEX Automations. This allows you to decide how often you want the synchronization to run. I have opted to sync daily at midnight UTC for the Locations synchronization.
Advanced Settings If you are worried about overloading the REST end-point, you can implement simple rate-limiting using the 'Enable Simple Rate Limiting' option.
A Word About Pagination Most REST services limit the number of rows they will return in one request. This reduces the load on the server hosting the REST service and provides easier-to-consume chunks of data for the consumer. You can specify how many rows you want to be returned on each page up to a maximum set by the owner of the REST service. If there are more rows to show, they will include links at the end of the response to the next and previous set of rows. This provides a small challenge to an automated data sync as you must cycle through all the pages to get the data. If the REST service is an ORDS service, then APEX has you covered, and the REST Synchronization will automatically step through all the pages. Since APEX 20.2, Oracle has introduced support for other simple pagination schemes. These include page size and fetch offset, page size, and the page number. You can also add custom pagination schemes via REST Data Source Connector Plug-ins.
Monitoring REST Synchronizations
Every time a REST Source Synchronization runs, messages are logged to the table 'apex_rest_source_sync_log'. The logs are visible from the REST Source Synchronization page (at the bottom of the page).

The following SQL could also be used to list the REST Sources for your application and show the last time the Synchronization ran and its result.
WITH last_run AS
(SELECT alog.rest_source_id
, alog.status
, alog.rows_processed
, EXTRACT(minute from end_timestamp - start_timestamp) duration_minutes
, EXTRACT(second from end_timestamp - start_timestamp) duration_seconds
FROM apex_rest_source_sync_log alog
WHERE synchronization_run_id = (SELECT MAX(alog1.synchronization_run_id)
FROM apex_rest_source_sync_log alog1
WHERE alog1.application_id = alog.application_id
AND alog1.rest_source_id = alog.rest_source_id))
SELECT aapp.application_name
, module_name
, module_static_id
, sync_type
, sync_table_name
, last_synchronization
, last_run.status last_run_status
, last_run.rows_processed last_run_rows
, last_run.duration_minutes last_run_mins
, last_run.duration_seconds last_run_secs
, credential_name
, data_profile_name
, credential_name
, url_endpoint
, auth_url_endpoint
, next_synchronization next_sync
, sync_is_active
, sync_table_owner
FROM apex_appl_web_src_modules aawsm
, apex_applications aapp
, last_run
WHERE aawsm.application_id = aapp.application_id
AND aapp.application_id = <APP_ID>
AND aawsm.module_id = last_run.rest_source_id (+)
ORDER BY aawsm.module_name;
OK, that’s it for the locations service and REST Synchronization, now let’s move on to the Tide Prediction service and talk about caching.
Tide Predictions Using REST Source Caching
If you enable caching for a REST Source, the REST service response is cached in a local table. This is important because subsequent calls to the web service will use the locally cached response, instead of making the round trip to the web service. A highly performant REST service (on a fast network) could get you a response back in fractions of a second. In view of this, caching may not seem like a big deal. However, given most REST sources are not that fast and that you may be calling 2 or 3 REST services for every page view, you could soon be adding a second or two to every page view if you did not use caching.
REST Source caching is configured from the REST Source 'GET' Operation definition page. For obvious reasons, you cannot configure caching for PUT,POST and DELETE REST operations.
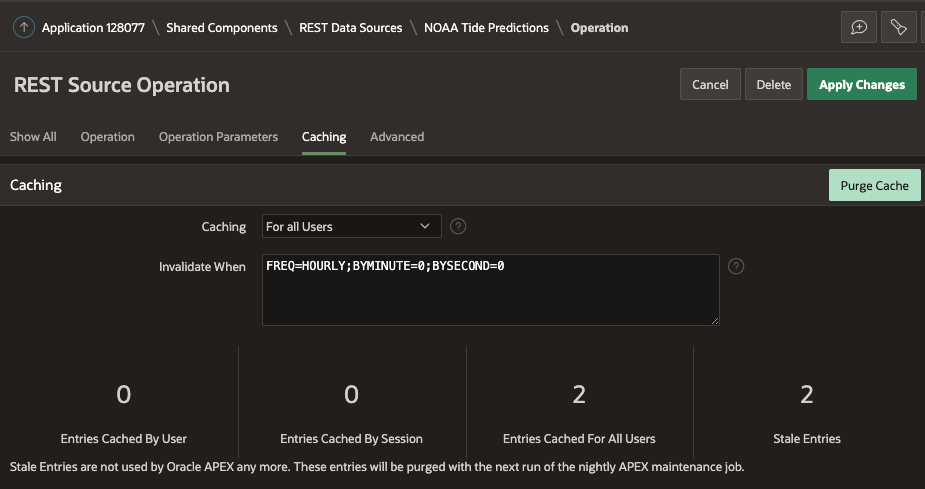
You have two levers you can use to fine tune caching:
Caching
- Disabled: Content is not cached and fetched from the REST source for each request.
- For all users: Content is cached and utilized by all users.
- By User: Content is cached specifically for each user.
- By Session: Content is cached specifically for each session.
In my example, the content is not user specific so I want to cache to be shared by 'all users'.
Invalidate When
You can use DBMS_SCHEDULER Calendaring Syntax to define a frequency for how long response payloads should remain in the local cache. In my example, I am invaliding the cache every hour. The reason I want to invalidate the cache every hour is to force APEX to fetch the latest results from the web service and refresh the cache.
Note: The entire un-parsed REST response payload CLOB is stored in the local table cache, not the individual rows and columns. This means that when APEX is using locally cached content, it has to parse the response in order to use it in an APEX component. Its not a big overhead but if you are joining the cached content to a local table you could see some performance impact.
How does APEX know if something is already in the cache? APEX uses the URL (with parameters) of the call to the REST service to determine if it already has the result in its cache.
For example. Assuming you are starting with nothing in the cache and make a call to the URL http://api.example.com/fetch_users?location=USA, APEX will call the REST service and cache the response. If you make another call to the exact same URL 5 minutes later, APEX it will realize it already has the cached response for this URL and use this instead of calling the web service again. If another 5 minutes later, you make a call to the slightly different URL http://api.example.com/fetch_users?location=UK, APEX will realize it does not have a cached response from this specific URL. APEX will call the REST service and cache the response for this URL ready for next time. The cached responses will remain in the local cache until they are cleared out based on the value you have set in the 'Invalidate When' field.
Water Levels (No Caching)
We discussed above that we want to fetch the 'Latest Tide Level' from the 'Water Level' REST service every page view without caching. You may think that would make this section of the blog post very short but there are still things you can do to improve performance.
Payload Size Aside from network latency, the size of a payload has the biggest impact on performance when considering REST service calls.
A large payload:
- Takes longer for the target REST service to process and generate the payload
- Takes longer for the network to transport back to APEX
- Takes longer for APEX to parse and process
The NOAA 'Water Level' REST service has parameters which allow you to filter the response based on a start and end date and time. If we request just the water levels from the past 10 minutes, we get 1 maybe 2 results. In the below example, we got a response back in 87ms and the payload size is just 783 bytes.
 If we push out the end_date parameter to get 10 days of data, we get response in 389ms (4.5 times slower) and a payload of nearly 19k (24 times larger).
If we push out the end_date parameter to get 10 days of data, we get response in 389ms (4.5 times slower) and a payload of nearly 19k (24 times larger).
 As well as the increased response time, we also have to consider that it will take APEX longer to parse and filter the larger payload.
As well as the increased response time, we also have to consider that it will take APEX longer to parse and filter the larger payload.
Parsing Method If you are using APEX REST Data Sources, then parsing will be taken care of by APEX. If you are calling a REST service from PL/SQL, then you need to consider how you parse the JSON response. If you are still using APEX_JSON to parse JSON in your PL/SQL code then I urge you to stop. Read my post For Speeds Sake, Stop Using APEX_JSON for more on why.
If you are running 12c (or higher) of the Oracle Database, native JSON parsing is orders of magnitude faster than APEX_JSON.
Conclusion
It may seem trite but performance is a journey and not a destination. Taking some extra time during design to consider performance and understanding what performance improving options are available are key. Many times people say I need the current/latest data without understanding the implications. Talk to your users and review the Prod and Cons of real time vs Near Real time data. Finally, understand that even when caching is not an option, it doesn't mean there is nothing you can do to improve performance.