Building Integrations with the Oracle DB APEX & ORDS - Part 3

Sending Data to Other Systems
Introduction
This is the final post in my series on "Building Cost-Effective Integrations with the RAD Stack" (Oracle REST Data Services, APEX, and the Database). In this post, I will focus on how we can send data to other systems with help from APEX and the Oracle Database.
You can 'send' data to other systems in two ways. One is to initiate sending data from the APEX / the database, and the other is to allow other systems to come and get the data they need whenever needed. I will discuss both approaches in this post.
3rd Party System Fetch
The most cost-effective way to send data to third-party systems is to create an ORDS REST API and allow the systems to access the data themselves.
With ORDS, this can be as easy as:
Write a SELECT Statement
Create a Module, Template & Handler
Secure the Module using OAuth2 Client Credentials
Add ORDS Roles & Privileges if Necessary
Publish Open API / Swagger Documentation to the Third Party
Optionally, educate the 3rd part developer on how ORDS query parameters work
Example
In this example, a customer with Oracle e-Business Suite must share current inventory levels with some of their Vendors/Suppliers. In this scenario, the vendor manages its inventory directly in the customer's warehouse. This is known as Vendor-Managed Inventory. From time to time, the Vendor needs to check the actual on-hand inventory levels.
This can be achieved by exposing an ORDS REST API to the Vendor. The API consists of a SELECT statement that queries a specific sub-inventory's current on-hand inventory levels. The diagram below describes the flow of information when the Vendor System makes a request.
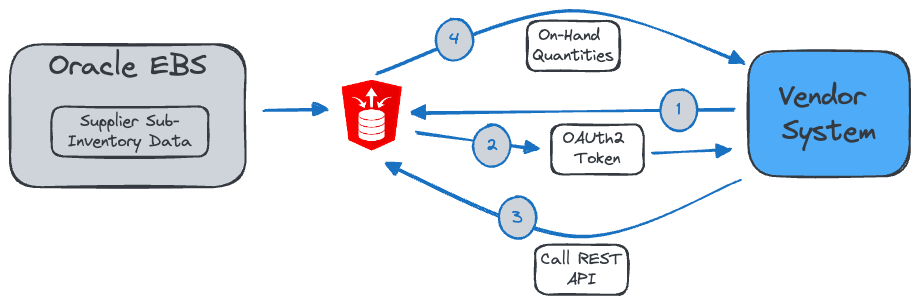
The Vendor System requests an OAuth token from ORDS, passing the Client ID and Client Secret we provide to the Vendor.
ORDS Returns the OAuth token to the Vendor System.
The Vendor System calls the ORDS REST API to get their current inventory levels. It passes the Bearer token obtained in the previous step to authenticate itself.
Before the ORDS API can return anything, it must first identify which Vendor made the request.
When an ORDS Service Secured by OAuth2 Client Credentials is called, ORDS Sets the bind variable called
:current_userwith the Client ID related to the Bearer token. If we create a unique set of OAuth2 credentials for each client, we can use this to identify which vendor is called the API.In a custom table in the EBS database, we can link the OAuth2 Client ID to an EBS Vendor and subinventory. We can then add a where clause to the SQL query in the ORDS service, which only returns on-hand quantities for the Vendor and Subinventory linked to the OAuth2 Client ID /
:current_user.
Finally, ORDS runs the SQL statement and returns a JSON-formatted response to the Vendor System.
The downside of this approach is that it puts more burden on the third-party system to manage OAuth credentials, call your REST API, and handle the response. Also, with most Cloud-based SaaS Systems, there is nowhere to add code to call your ORDS REST Services.
Other examples where I have followed this approach include:
Build ORDS REST APIs that allow Autodesk Vault to fetch Items and Bill of Material Details from Oracle EBS.
Build ORDS REST APIs that allow OnBase to fetch Vendors from Oracle EBS.
APEX Initiates Send
If the 3rd party system cannot come and get the data it needs, you must send it to the 3rd party system. This is going to be the case for integrations with most SaaS systems.
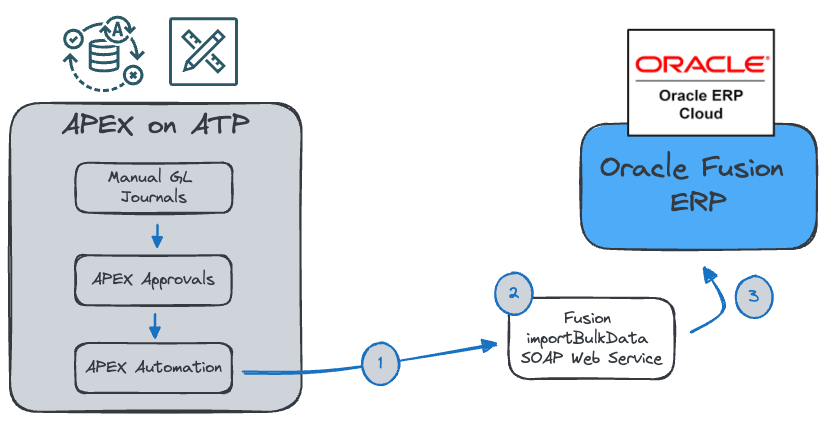
In the above example:
Users enter manual General Ledger Journal entries in an APEX Application.
Users submit completed Batches for approval via APEX Workflow.
After approval, a scheduled APEX Automation gathers approved batches and calls the Fusion REST Web Service erpintegrations to post them to Fusion General Ledger.
The Web Service orchestrates importing the data to Fusion Interface tables, validating the data, and creating Journals in General Ledger.
When to Send the Data
A major consideration when sending data to other systems is when to send it. The answer to this question is often driven by how up-to-date the data needs to be in the target system.
On a Schedule
Sending data to other systems regularly is a scalable and relatively easy-to-implement approach. APEX provides excellent scheduling capabilities via APEX Automations. APEX Automations provides an easy-to-use interface on the native Oracle Database Scheduler. It comes with many features useful to developers, including logging and error handling. Please read my blog post, "Scheduling Made Easy with APEX" for more on APEX Automations.
When sending data on a schedule, you need to either:
Identify the last update date type column in the source data that indicates when a record has been created or updated. Only the changed records are sent to the target system when the scheduled integration runs.
As records change, add them to a queue. When the scheduled integration runs, only the queued records are sent to the target system.
Once you have identified the records to send, you need to format the data in the format the target system REST API expects, handle Authentication for the target system REST API, and then call it.
Real-Time
Most users will tell you they need the interface to run in real time. If you hear this requirement, I urge you to investigate and ensure it is necessary. Real-time integration is more expensive to build and support.
While sometimes necessary, sending data to other systems can be difficult to implement and scale. An excellent alternative is to employ a queue. This could be an Oracle Advanced Queue table in the database or a Queuing Service like the OCI Queue Service. See my post, 'Setting up and Using the OCI Queue Service from APEX', for more details on the OCI Queue Service.
Queueing offers several advantages over processing transactions in real-time:
Improved System Stability: Queues help decouple a system's components. When transactions are processed in real time, any failure in one part can ripple through the entire system. Queues act as shock absorbers, allowing one part of the system to fail or slow down without immediately impacting others.
Load Balancing: In real-time processing, sudden spikes in demand can overwhelm a system. Queues help mitigate this by acting as buffers. They can hold onto transactions during peak times and process them as the system's capacity allows, thus evenly distributing the load over time.
Scalability: Using queues makes it easier to scale a system horizontally (adding more machines). You can add more consumers to process the transactions in the queue without affecting the rest of the system's architecture.
Asynchronous Processing: Queues allow for asynchronous processing, where the sender of a message or transaction doesn’t need to wait for the receiver to process it. This can greatly improve a system's efficiency, especially in cases where the processing part is time-consuming.
Enhanced Reliability and Error Handling: In a direct processing model, if a transaction fails, it can be challenging to handle this gracefully. With queues, you can design sophisticated retry mechanisms and move problematic transactions to a separate queue for later analysis without impacting the overall flow.
Data Consistency: In distributed systems, ensuring data consistency across different components can be challenging. Queues can help by serializing access to shared resources, simplifying the process of keeping data consistent across the system.
Predictable Performance: With real-time processing, the system's performance can be unpredictable under different loads. Queues make performance more predictable by smoothing out the processing over time, regardless of the load.
Analytics and Monitoring: Queues can be instrumented to provide valuable insights into the flow of transactions through the system, which can be vital for monitoring performance and predicting future scaling needs.
Prioritization: Certain transactions can be prioritized over others in a queue, which is more complex to achieve in a real-time processing scenario.
Fault Tolerance and Recovery: In case of system crashes or failures, queued transactions can be recovered and reprocessed, ensuring that no data is lost, which is a critical aspect for many business applications.
Here is an example of an integration that utilizes a queue to send scanned AP Invoices to Oracle Fusion ERP.
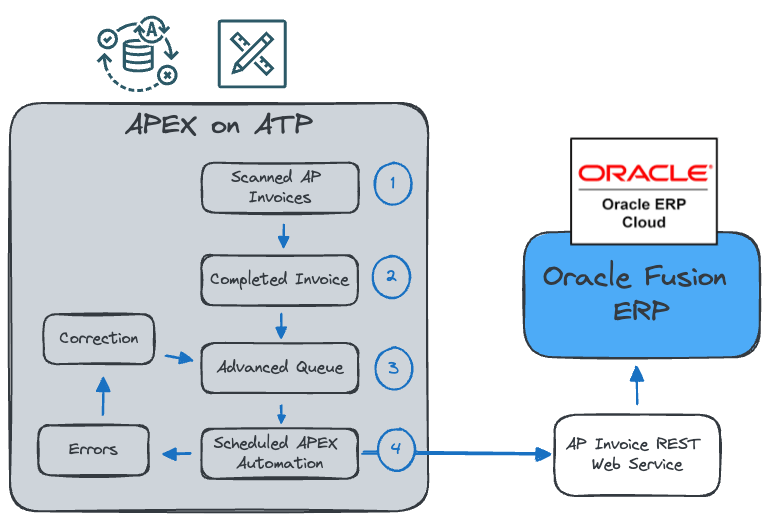
An API invoice is scanned and loaded into a table.
The invoice is verified, and missing details are added.
The invoice has been added to an outbound queue table.
A scheduled APEX Automation calls a Fusion API to create the invoice in Fusion. If the REST API fails, the invoice is added to an error queue for manual correction. Once corrected, it is re-added to the outbound queue and picked up by the APEX Automation the next time it runs.
How to Send Data
When sending data to external web services, the APEX_WEB_SERVICE PL/SQL API is my tool of choice. It allows you to call almost any REST or SOAP-based web service from PL/SQL. It integrates with APEX Web Credentials to ensure a secure and seamless experience when dealing with Web Services with various authentication mechanisms.
Error Handling & Monitoring
However you send data to the target system, you need to handle potential errors and inform people when errors occur. I usually create a custom log table for outbound integrations from the database to store details of each outbound web service request. This works well when calling APEX_WEB_SERVICE, as I can control when to populate the log table. The log table contains columns like the time the request was sent, the payload sent, the response received from the target API, and the payload received by the target API.
Use this log table in conjunction with the standard log table apex_webservice_log, to determine when outbound web service calls have failed. I typically build an APEX Automation, which periodically checks these logs and sends a digest email using apex_mail when they do.
Handling Large Volumes
You must use the most efficient approach when fetching and processing tens or hundreds of megabytes of data. When fetching data from other systems, four areas can affect performance when dealing with large volumes:
Network Latency (how long it takes to transport the data over the network)
Performance of the 3rd Party System (how long it takes the 3rd party system to generate the data)
Parsing the Response (how long it takes to parse the response JSON, XML, etc., into a format SQL can use).
Processing the Response into Local Tables (how long it takes to INSERT, MERGE the data into your local DB table).
The following tips can help reduce the performance impact on each of the above areas when dealing with large volumes of data:
Only fetch the rows you need:
- If the target system API allows you to provide query criteria, you can use it to fetch only the rows you need.
Only fetch the columns you need:
- If you are calling a Graph API or can control the columns in the response, then limit the columns to just the ones you need.
Model different pagination options:
- If the target API uses pagination, you should model different pagination sizes to determine whether it is better to have more smaller requests or fewer larger requests. The trade-off here is network latency vs. the processing capabilities of the target API and your local system.
If you control the target API, have it generate zipped responses; this reduces the payload size crossing the network.
Use native database parsers where possible. For example, even though CSV files are much smaller than JSON files, you can usually parse JSON files much faster because you can use the native DB parser JSON_TABLE instead of the PL/SQL parser used by APEX_DATA_LOADER.
Look at other approaches for loading data:
- DBMS_CLOUD.COPY_DATA utilizes SQL*Loader to load data from various Cloud Provider Object Storage Services. In my testing, it can be up to 5x faster than using REST APIs. Read my post, '5X File Loads from Object Storage with DBMS_CLOUD.COPY_DATA' to find out more.
Conclusion
This is the final post in my integration series. I hope you have concluded (as I have) that the combination of APEX, ORDS, and the Oracle Database is a powerful combination in the integration space.
Other Posts in this Series
Post 1 - Fetching Data from Other Systems
Post 2 - Receiving Data from Other Systems